
gyunggyung/ALBERT-Text-Classification
ALBERT Text Classification. Contribute to gyunggyung/ALBERT-Text-Classification development by creating an account on GitHub.
github.com
코드 위치는 깃허브에 있습니다!!
아래 라이브러리를 써서 아주 간단하게 text classification을 하는 방법을 알아볼 것이다. 먼저 아래 라이브러리를 설치하자. 참고로 tf2 버전을 사용한다.
pip install ktrainamaiya/ktrain
ktrain is a Python library that makes deep learning and AI more accessible and easier to apply - amaiya/ktrain
github.com
- BERT: bert-base-uncased, bert-large-uncased, bert-base-multilingual-uncased, and others.
- DistilBERT: distilbert-base-uncased, distilbert-base-multilingual-cased, distilbert-base-german-cased, and others
- ALBERT: albert-base-v2, albert-large-v2, and others
- RoBERTa: roberta-base, roberta-large, roberta-large-mnli
- XLM: xlm-mlm-xnli15–1024, xlm-mlm-100–1280, and others
- XLNet: xlnet-base-cased, xlnet-large-cased
위와 같은 모델들을 사용할 수 있다. 원하는 모델을 사용하자.

먼저 자신의 데이터셋을 받는다.

그리고 라벨 값들을 받는다.

원활한 학습을 위해서 셔플을 진행한다.

학습 데이터와 라벨 데이터를 나눈다. 그리고 ktrain을 import 하고 우리가 원하는 모델을 지정한다. 일단 bert-base를 사용하겠다. 원한다면, 다른 모델을 사용하면 된다.
모델 이름, 시퀀스 길이를 인자로 사용한다. BERT 기반 모델의 최대 시퀀스 길이는 일반적으로 512이다. 토큰 maxlen보다 작은 문서는 패딩으로 채워지고 maxlen토큰 보다 큰 문서는 잘린다.

그런 다음 훈련 및 유효성 검사를 진행한다. 데이터 세트를 선택한 사전 훈련된 모델 (이 경우 ALBERT)에 필요한 형식으로 전처리를 진행한다.

그리고 학습을 위해서 trn, val 데이터를 나눈걸 pre-process을 진행한다.
다음으로 pre-train 된 가중치와 임의로 조정할 수 있는 임의로 초기화 된 최종 레이어로 분류기를 정의한다. 모델은 ktrain Learner 객체 래핑되어 모델을 쉽게 학습 및 검사하고, 모델을 사용하여 새 데이터를 예측할 수 있다.

모델을 받고 학습 준비를 끝냈다. 그럼 이제 학습을 하자.
참고로 BERT 기반 모델의 경우 2e-5 와 5e-5 사이의 학습 속도는 일반적으로 광범위한 데이터 세트에서 잘 작동한다. 교육을 위해, 우리는 fit_onecycle메서드를 호출한다. 잘 작동하는 것이 보인다.
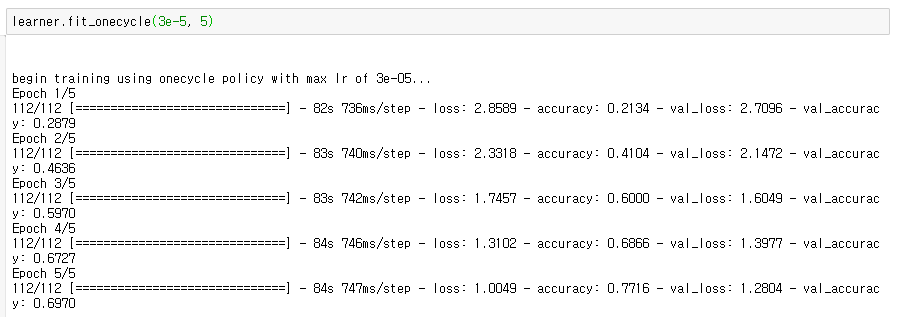
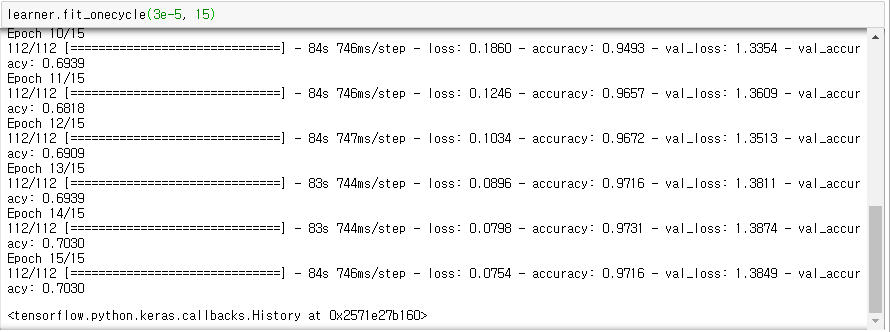
간단하게 predictor를 하면 잘 되는 것이 보인다.

참고
Text Classification with Hugging Face Transformers in TensorFlow 2 (Without Tears)
The Hugging Face transformers package is an immensely popular Python library providing pretrained models that are extraordinarily useful…
towardsdatascience.com
'AI 이야기' 카테고리의 다른 글
| 프로그래머가 대체될 수도 있다는 생각을 딱히 못했는데... (0) | 2021.06.13 |
|---|---|
| 한국어 가사 데이터 KoGPT2 Fine Tuning (1) | 2020.04.26 |
| KoGPT-2 를 이용한 인공지능 가사 생성 (0) | 2020.04.24 |
| 인공지능이 작성하는 한국어 기사 (2) | 2020.03.28 |
| NLP Papers list (0) | 2020.02.26 |



