
모델 구조

둘 비교라네요
https://parl.ai/projects/blenderbot2/
Blenderbot2
BlenderBot 2.0: An open source chatbot that builds long-term memory and searches the internet A chatbot with its own long-term memory and the ability to access the internet. It outperforms existing models in terms of longer conversations over multiple sess
parl.ai

와...
- Facebook AI Research has built and open-sourced BlenderBot 2.0, the first chatbot that can simultaneously build long-term memory it can continually access, search the internet for timely information, and have sophisticated conversations on nearly any topic. It’s a significant update to the original BlenderBot, which we open-sourced in 2020 and which broke ground as the first to combine several conversational skills — like personality, empathy, and knowledge — into a single system.
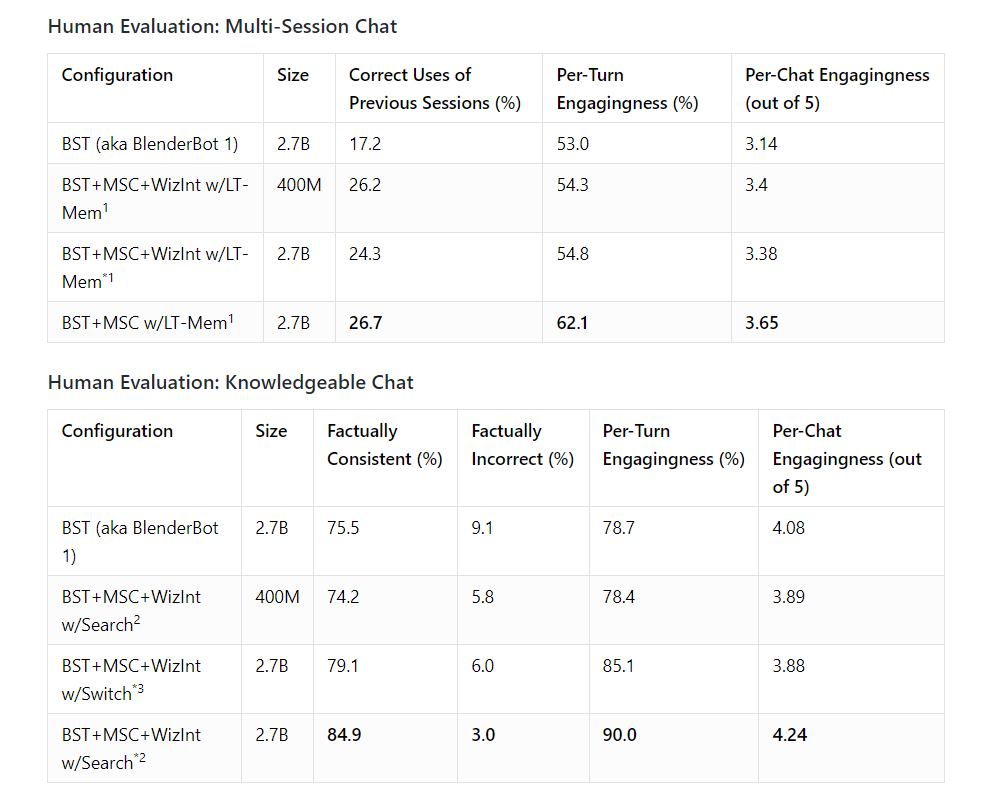
- When talking to people, BlenderBot 2.0 demonstrated that it’s better at conducting longer, more knowledgeable, and factually consistent conversations over multiple sessions than its predecessor, the existing state-of-the-art chatbot.
- The model takes pertinent information gleaned during conversation and stores it in a long-term memory so it can then leverage this knowledge in ongoing conversations that may continue for days, weeks, or even months. The knowledge is stored separately for each person it speaks with, which ensures that no new information learned in one conversation is used in another.
- During conversation, the model can generate contextual internet search queries, read the results, and incorporate that information when responding to people’s questions and comments. This means the model stays up-to-date in an ever-changing world.
- Today we’re releasing the complete model, code, and evaluation setup, as well as two new conversational data sets — human conversations bolstered by internet searches, and multisession chats with people that reference previous sessions — used to train the model, so other researchers can reproduce this work and advance conversational AI research.
- Blender Bot 2.0: An open source chatbot that builds long-term memory and searches the internet https://ai.facebook.com/blog/blender-bot-2-an-open-source-chatbot-that-builds-long-term-memory-and-searches-the-internet
NLP의 끝은 어디일까요? 멋집니다! Facebook
Blenderbot2
BlenderBot 2.0: An open source chatbot that builds long-term memory and searches the internet A chatbot with its own long-term memory and the ability to access the internet. It outperforms existing models in terms of longer conversations over multiple sess
parl.ai
Blender Bot 2.0: An open source chatbot that builds long-term memory and searches the internet
Facebook AI Research has built and open-sourced BlenderBot 2.0, the first chatbot that can simultaneously build long-term memory it can continually access, search the internet for timely information, and have sophisticated conversations on nearly any topic
ai.facebook.com
Facebook's BlenderBot 2.0 chatbot can learn and remember new things by itself - SiliconANGLE
Facebook's BlenderBot 2.0 chatbot can learn and remember new things by itself - SiliconANGLE
siliconangle.com
아래 뉴스들을 번역한 기사를 통해서 쉽게 읽어보죠!
[이슈] GPT-3 넘었다, 실시간 정보로 대화할 수 있는 인공지능 개발!... 페이스북 AI, 혁신적인 AI 챗봇 ‘블렌더봇 2.0’ 오픈 소스로 공개
GPT-3와 페이스북 AI의 블렌더봇 첫 번째 버전과 같은 인공지능(AI) 언어 생성 모델은 적어도 진행 중인 대화의 맥락에서 자신을 명확하게 표현하고 현실적으로 보이는 텍스트를 생성할 수 있다. 하지만, 그들은 매우 짧은 기억력과 정적인 정보로 이전에 학습된 것에 한정되어 있다.
즉, 그들은 이전에 학습한 것에 국한된다는 것으로 결코 추가적인 지식을 얻을 수 없다는 것이다. 예를 들어, GPT-3와 이전의 블렌더봇은 NFL 슈퍼스타 톰 브래디(Tom Brady)가 여전히 뉴잉글랜드 패트리어츠(New England Patriots)에 있다고 믿고 있으며, 그가 탬파베이 부케너스(Tampa Bay Buccaneers)와 함께 2021년 슈퍼볼에서 우승했다는 것을 알지 못한다.
게다가 그들은 과거의 인기 있는 TV쇼와 영화에 대해 알고 있지만, 미국의 슈퍼히어로 드라마 완다비전(WandaVision)과 같은 새로운 시리즈에 대해서는 전혀 알지 못한다.
다시 말해, 어제 GPT-3나 블렌더봇에 뭔가 얘기했다면 오늘 대화에서는 어제의 기억을 잊어버린다. 여기에, 더 안좋은 것은 알고리즘의 결함 때문에 모델들은 환각적인 지식(Infamously Hallucinate knowledge)으로 즉, 정확하지 않은 정보를 자신 있게 이야기한다.
이에 페이스북 AI 연구소(Facebook AI Research)는 지속적으로 접속할 수 있는 장기기억장치(Long-Memory)를 구축하고 현재까지의 어떤 모델보다 실시간 인터넷 검색과 거의 모든 주제에 대한 정교한 대화 등을 동시에 할 수 있는 성능이 뛰어나고 더 인간적인 느낌을 줄 수 있는 새로운 인공지능(AI) 챗봇 '블렌더봇 2.0 (BlenderBot 2.0)'모델과 데이터 세트를 16일(현지시간) 오픈소스로 공개했다.
이 솔루션은 인성, 공감, 지식과 같은 여러 대화 기술을 단일 시스템으로 결합한 최초의 AI 챗봇으로 사람들과 대화할 때, 지난해 5월 공개한 이전 모델인 ‘블렌더 1.0(BlenderBot 1.0)’ 보다 다양한 세션에서 더 길고, 더 박식하며, 사실적으로 일관된 대화를 구사한다.
특히, 이 모델은 대화중에 수집한 관련 정보는 장기기억에 저장하므로 며칠, 몇 주 또는 몇 달 동안 계속될 수 있는 지속적인 대화에서 이 지식을 활용할 수 있다. 또 지식은 대화하는 사람마다 별도로 저장된다. 단, 한 대화에서 학습된 정보는 다른 대화에서 사용되지 않는다.
또한 대화중에 이 모델은 상황별 인터넷 검색 쿼리를 생성하고 결과를 읽고 사람들의 질문과 의견에 응답할 때 그 정보를 통합할 수 있다. 이것은 그 모델이 끊임없이 변화하는 세계에서 학습하고 최신 상태를 유지한다는 것을 의미한다.
페이스북 AI는 전체 모델, 코드 및 평가 설정을 공개하고, 인터넷 검색으로 강화된 인간 대화와 이전 세션을 참조하는 사람들과의 다중 세션 채팅 등 두 가지 새로운 대화 데이터 세트 역시 공개해 전 세계 연구자 및 개발자들이 이 모델을 재현하고 대화 AI 연구를 진전시킬 수 있도록 했다.
새로운 AI 대화형 모델 '블렌더봇 2.0 (BlenderBot 2.0)'은 많은 작업에서 대화 모델을 공유하고 학습 및 평가하기 위한 페이스북의 오픈소스 통합 플랫폼인 팔에이아이(ParlAI-다운)를 기반으로 한다. 또한 기억에 접근하고 환각(Infamously)을 줄이는 능력으로 블렌더봇 2.0은 공감, 지식, 성격 등 다양한 대화 기술을 한 시스템에서 혼합한 최초의 AI 챗봇인 블렌더봇 1.0 버전(2020.5.2, 본지 기사 참조)을 기반으로 한다.
언어 모델 생성에 대한 연구가 빠르게 진행되고 있으며, 산업으로서 우리는 챗봇의 대화 능력을 크게 확장하기 위한 그 어느 때보다도 더 좋은 도구를 가지고 있다. 기존의 시스템은 음식, 영화, 밴드 같은 것에 대한 기본적인 질문을 하고 대답할 수 있다. 예를 들어, 그들은 현재, 톰 브래디(Tom Brady’s)는 탬파베이 버커니어스(Tampa Bay Buccaneers) 소속이며 포지션은 쿼터백이며, 그에 대한 경력 등을 자세히 토론하는 것과 같은 더 복잡하거나 자유로운 대화에는 여전히 먹통이다.
그러나 위에서 언급했듯이 블렌더봇 2.0에 기반 한 기술은 며칠, 몇 주, 심지어 몇 달 동안 지속될 수 있는 어떤 주제에 대해서도 멀티세션 대화를 할 수 있고, 대화가 진화함에 따라 알고 말할 수 있는 것을 더함으로써 일상생활과 비지니스에 유용하게 사용될 수 있을 것으로 예상된다.
이처럼 블렌더봇 2.0은 대화중에 인터넷 검색 쿼리를 생성하고, 최신 상태를 유지, 지식과 정보를 구축하고, 사용하고 이전 아이디어를 다시 언급할 수 있는 최초의 진정한 AI 챗봇으로 인터넷을 통해 관련 정보를 저장하고 대화를 확대하는 능력을 포함한 이러한 발전은 현재의 AI 대화형 시스템의 단점을 극복한 것으로 기존 시스템의 대화 능력을 훨씬 능가한다고 한다.
이 능력을 통해 모델은 인터넷에서 사용할 수 있는 광범위한 주제 중에서 현재, 진행 중인 최신 스포츠 경기 결과와 영화 또는 TV 프로그램뿐 아니라 최신 리뷰를 대화 내용에 잠재적으로 포함시킬 수 있다. 이는 모델은 사실적인 사실에 기반하고 자의적으로 추론하지 않는다는 것을 의미한다.
블렌더봇 2.0은 페이스북의 오픈 소스인 지능형 자연어처리(NLP) 모델 생성을 간소화하는 '검색 증강 생성(Retrieval Augmented Generation-다운)' 모델을 기반으로 이 접근 방식은 대화 자체에 포함된 지식을 넘어서는 대화 응답을 생성할 수 있도록 한다. 대화중에 정보 검색 구성 요소와 seq2seq 생성기를 결합한 모델은 장기 메모리와 인터넷을 검색하여 찾은 문서 모두에서 관련 정보를 찾는다.
이를 위해 대화 컨텍스트에서 관련 검색 쿼리를 생성하는 추가 신경망 모듈로 기존 인코더-디코더 아키텍처를 보강한다. 그런 다음 블렌더봇 2.0은 Fusion-in-Decoder 방법을 사용하여 인코딩된 대화 기록에 결과 지식을 추가한다.
이를 위해, 대화 컨텍스트에서 관련 검색 쿼리를 생성하는 추가 신경망 모듈로 기존 인코더-디코더 아키텍처를 보강한다. 여기서, 일반적인 접근 방식은 수십억 개의 매개변수가 있는 모델을 사용해야 하지만, 블렌더봇 2.0은 퓨전-인-디코더(Fusion-in-Decoder-논문 다운) 방법을 사용하여 인코딩된 대화 기록에 결과 지식을 추가한다.
마지막으로, 이 인코딩된 지식을 고려하면서 블렌더봇 2.0은 응답을 생성하며, 챗봇의 장기 메모리 저장소에서 꺼내어 거기에 무엇을 추가할지 결정한다. 여기에는 대화 컨텍스트에 기초하여 저장될 메모리를 생성하는 추가 신경 모듈을 사용한다.
결론적으로 대표적인 AI 대화 모델의 현재 동향은 상당한 컴퓨팅 리소스가 필요한 점점 더 큰 모델로 학습에 집중하는 것이다. 또, 이러한 모델은 학습한 내용을 모델 가중치에 저장하려고 한다. 그러나 항상 새롭게 생산되는 데이터와 변화하고 있는 세상의 정보 전체를 담는 것과 인터넷에 펼쳐진 모든 정보는 저장하는 것은 거의 불가능하다.
즉, 이번에 페이스북 AI가 공개한 블렌더봇 2.0은 그 방법 대신에 이전에 학습한 것에 국한하지 않고 지속적으로 접속할 수 있는 장기기억장치(Long-Memory)를 구축하고 실시간 인터넷 검색에 기반 한 세상의 모든 정보와 모든 주제에 대한 정교한 대화 등을 동시에 구사할 수 있는 혁신적인 AI 시스템이자 대화형 인공지능에서 새로운 패러다임으로 평가된다.
또한, 우리는 한동안 개인정보 보호나 정제되지 않은 단어사용, 차별 또는 혐오 발언으로 이슈 한 가운데 있었던 AI대화 모델 ‘이루다’ 사태로 경험했듯이 페이스북 AI는 블렌더봇 2.0에서도 이러한 문제를 사전에 완화하기 위해 대규모 연구를 수행고 안전과 어려운 프롬프트에 대한 견고성이라는 두 가지 새로운 방법을 개발하고 모델에 포함시켰다.
이 방법을 통해 자동화된 분류기로 측정한 공격적 반응을 90% 감소시키는 동시에 실제 사람들과의 대화에서 안전 지수를 74.5% 증가시켰으며, 인간 평가자를 대상으로 한 실험에서 이 위험을 어느 정도 완화시켰다고 밝혔지만 처음 시도되는 모델이라 여기에 더 집중할 것이라고 밝혔다.
또한, 페이스북은 "우리는 인간이 보는 것처럼 의사소통과 이해를 위해 만들어진 에이전트의 대화뿐만 아니라 말할 수 있는 날을 고대한다. 우리는 멀티모달 블렌더봇 다음 단계로는 AI 가상의 조수나 디지털 친구와 같은 애플리케이션에서 발전시킬 수 있다고 생각한다"고 밝혔다.
또한 "이 블렌더봇 2.0 릴리스와 해당 데이터 세트가 다양한 산업과 비즈니스에 그리고 전 세계 연구자 및 개발자들에게 더 많은 진전을 이루도록 도울 수 있기를 바란다"고 덧붙였다.
한편, 이번 AI 챗봇 '블렌더봇 2.0' 개발 및 연구에 기반이 된 논문은 '인터넷 증강 대화 생성(Internet-Augmented Dialogue Generation-다운)' 과 '금붕어 기억 너머:장기적인 개방형 도메인 대화(Beyond Goldfish Memory: Long-Term Open-Domain Conversation-다운) 두가지이며, 오픈 소스로 공개된 개발된 AI 챗봇 '블렌더봇 2.0' 의 코드 및 데이터 세트는 누구나 이용해 연구 및 개발에 적용(다운)할 수 있다.
출처 : 인공지능신문(http://www.aitimes.kr)
http://www.aitimes.kr/news/articleView.html?idxno=21724&fbclid=IwAR2UeUvPZTKJGpfmBOUf8bjcGg0MUgHHzryuVTieZ9fSRDMNsy9NZZBH06U
[이슈] GPT-3 넘었다, 실시간 정보로 대화할 수 있는 인공지능 개발!... 페이스북 AI, 혁신적인 AI 챗
GPT-3와 페이스북 AI의 블렌더봇 첫 번째 버전과 같은 인공지능(AI) 언어 생성 모델은 적어도 진행 중인 대화의 맥락에서 자신을 명확하게 표현하고 현실적으로 보이는 텍스트를 생성할 수 있다.
www.aitimes.kr
더 자세한 내용을 이해하기 위해서는, 논문으로 읽어보는 것도 좋죠! 그리고 관련 코드도요!
- https://arxiv.org/pdf/2004.13637.pdf
- https://arxiv.org/pdf/2004.08449.pdf
- https://github.com/facebookresearch/ParlAI
- https://www.parl.ai/docs/tutorial_quick.html

https://arxiv.org/pdf/2004.13637.pdf

https://arxiv.org/pdf/2004.13637.pdf

이걸로

이런 게
되네

역시 파라미터 수가

깡패요

진리니라

https://arxiv.org/pdf/2004.08449.pdf

믿습니다

https://github.com/facebookresearch/ParlAI
GitHub - facebookresearch/ParlAI: A framework for training and evaluating AI models on a variety of openly available dialogue da
A framework for training and evaluating AI models on a variety of openly available dialogue datasets. - GitHub - facebookresearch/ParlAI: A framework for training and evaluating AI models on a vari...
github.com
미래가 기대됩니다! 과연 챗봇의 미래는? 요즘 페이스북의 폼이 미쳤습니다.
5 top chatbot features to boost your AI plan
The top chatbot features can help enterprises enhance their bots, making them understand customer queries better and work in more channels.
searchenterpriseai.techtarget.com
Facebook shelves its brain-reading interface project to move in a different direction - SiliconANGLE
Facebook shelves its brain-reading interface project to move in a different direction - SiliconANGLE
siliconangle.com
그런데..... 페이스북을 사용하면, 진짜 여기가 페이스북인가? 싶습니다. 어떻게 이렇게 앱이 느리지... php를 왜 쓰는 거지, 웹에서는 거의 동작을 안 합니다..
와 내가 만들어도 이거보다는 잘 만들지 않을까? 논문을 보면 기술력이 있는데, 신기하네...
정말 같은 회사가 맞나요? ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
'AI 이야기' 카테고리의 다른 글
| 인공지능의 미래 | 새로운 지능은 어떻게 만들어질 것인가? (0) | 2021.07.27 |
|---|---|
| 새로운 인공지능의 미래 | GLOM, FermiNet, QNN이 만드는 새로운 딥러닝 (0) | 2021.07.27 |
| 프로그래머가 대체될 수도 있다는 생각을 딱히 못했는데... (0) | 2021.06.13 |
| 한국어 가사 데이터 KoGPT2 Fine Tuning (1) | 2020.04.26 |
| KoGPT-2 를 이용한 인공지능 가사 생성 (0) | 2020.04.24 |



