
2018년 등장한 BERT는 NLP Task에서 압도적인 성능을 보여줬습니다. 시간이 지난 지금 BERT를 기반의 다양한 모델이 많이 등장했습니다. 다양한 모델의 핵심적인 아이디어를 공유해보겠습니다. 혹시라도 틀린 부분이 있다면, 댓글로 알려주시길 바랍니다.
아래 내용은 수다르산 라비찬디란 저 구글 BERT의 정석을 많이 참고하여 작성했습니다. 이 글이 구글 BERT의 정석 요약 및 보충이라고 볼 수도 있겠습니다. 각 모델을 더 공부하고 싶은 분들은, 설명 시작 부분에 논문 링크를 넣었으니 논문을 읽어보시기 바랍니다.
구글 BERT의 정석
인간보다 언어를 더 잘 이해하고 구현하는 고성능 AI 언어 모델 BERT. 이 책은 자연어 응용 분야에서 상당한 성능 향상을 이뤄 주목받고 있는 BERT 모델을 기초부터 다양한 변형 모델, 응용 사례까
www.aladin.co.kr
BERT

BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 논문에서 나온 모델입니다. 해당 모델은 Transformer Encoder를 이용해서 만들었습니다.

BERT는 두 개의 문장 쌍을 입력받습니다. 입력(Input)의 시작 부분에 CLS token을 넣습니다. 각 문장의 끝에는 SEP token을 넣습니다. 만약 입력 문장의 크기가 BERT dimension보다 작다면, 그 차이만큼 PAD token을 채워줍니다. 참고로 CLS token에는 문장의 모든 정보가 순수하게 들어있어, 각종 Classification take에 사용됩니다.
입력 문장을 Token Embedding, Segmet Embedding, Position Embedding 하여 Model에 입력합니다. Token Embedding은 WordPiece로 입력 문장을 tokenization 합니다. Segmet Embedding은 입력 문장 쌍을 구분하는 데 사용됩니다. 첫 번째 문장을 EA, 두 번째 문장을 EB로 구분합니다. Position Embedding은 Transformer와 다르게 순서만 넣어, BERT Training 과정에서 학습시킵니다.

MLM, NSP로 BERT를 Pre-training 시킵니다. NSP(Next Sentence Prediction)는 2개의 문장이 이어지는지 확인하는 task입니다.
MLM(Masked LM)은 입력 문장의 15%를 랜덤 하게 maksing 하고 이를 유추하는 Task입니다. BERT는 WordPiece를 사용하여 tokenization 합니다. 따라서 하나의 단어가 여러 token으로 나눠질 수 있습니다. MLM에서는 하나의 단어가 여러 token으로 나눠지는 경우, 해당 token을 모두 maksing 합니다. Fine-Tuning시에는 입력 문장 masking을 진행하지 않습니다. 이런 괴리를 줄이기 위해서 masking 하는 token의 80%만 masking을 진행합니다. 남은 10%의 token은 그대로 입력시킵니다. 나머지 10%는 다른 token을 입력시킵니다.
ALBERT

ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS 논문에서 나온 모델입니다. ALBERT는 효율적인 방법으로 Model Size를 줄이면서, 높은 성능을 유지합니다.
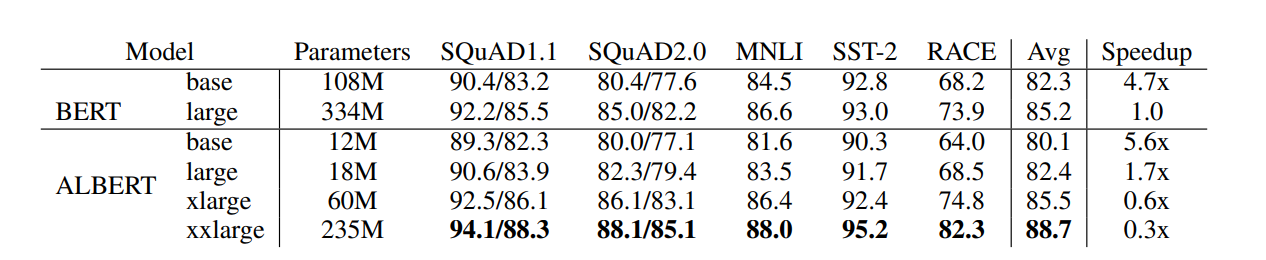
ALBERT는 layer간 모든 parameter를 공유합니다. ALBERT는 Input Token Embedding size(E)를 Hidden Size(H) 보다 줄입니다. Vocabulary Size를 V라고 합시다. BERT의 Embedding size는 V * E입니다. ALBERT는 Embedding size를 행렬 분해하여 V * H + E * H로 줄입니다. 마지막으로 NSP take 대신 SOP(Sentence Order Prediction)를 사용합니다. SOP는 문장 순서가 맞는지 확인하는 task입니다.
RoBERTa
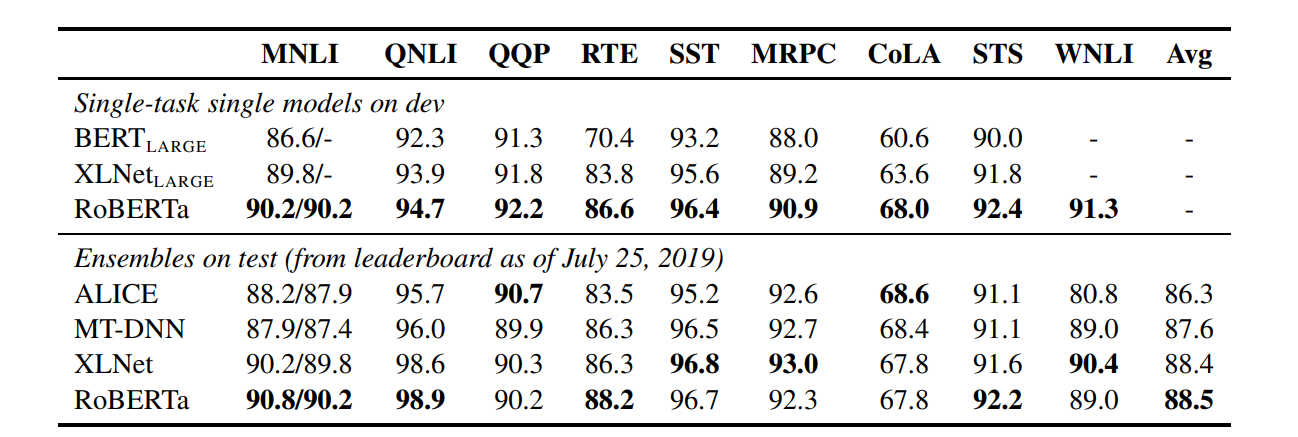
RoBERTa: A Robustly Optimized BERT Pretraining Approach 논문에서 나온 모델입니다. RoBERTa는 높은 성능으로 유명합니다.
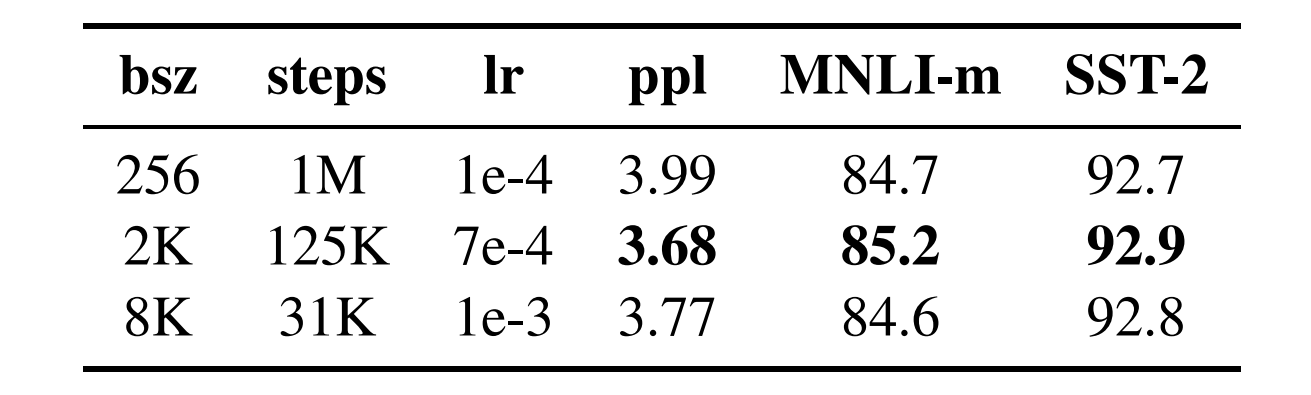
RoBERTa는 NSP task가 비효율적이라고 판단하여 MLM task만 진행합니다. MLM 과정에서 Epoch마다 다시 masking을 진행합니다. 더 많은 데이터와 더 큰 batch size로 학습을 진행합니다. 마지막으로 byte-level BPE로 tokenization 합니다.
ELECTRA
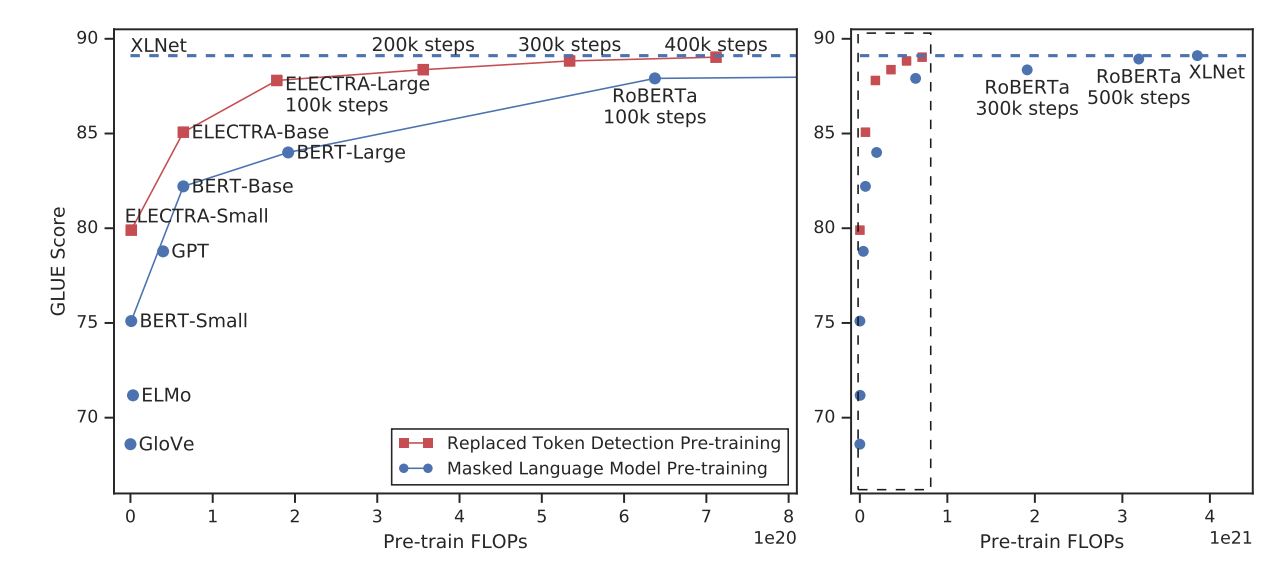
ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS 논문에서 나온 모델입니다. ELECTRA는 Generator와 Discriminator를 이용하여 매우 효율적인 학습을 진행합니다.
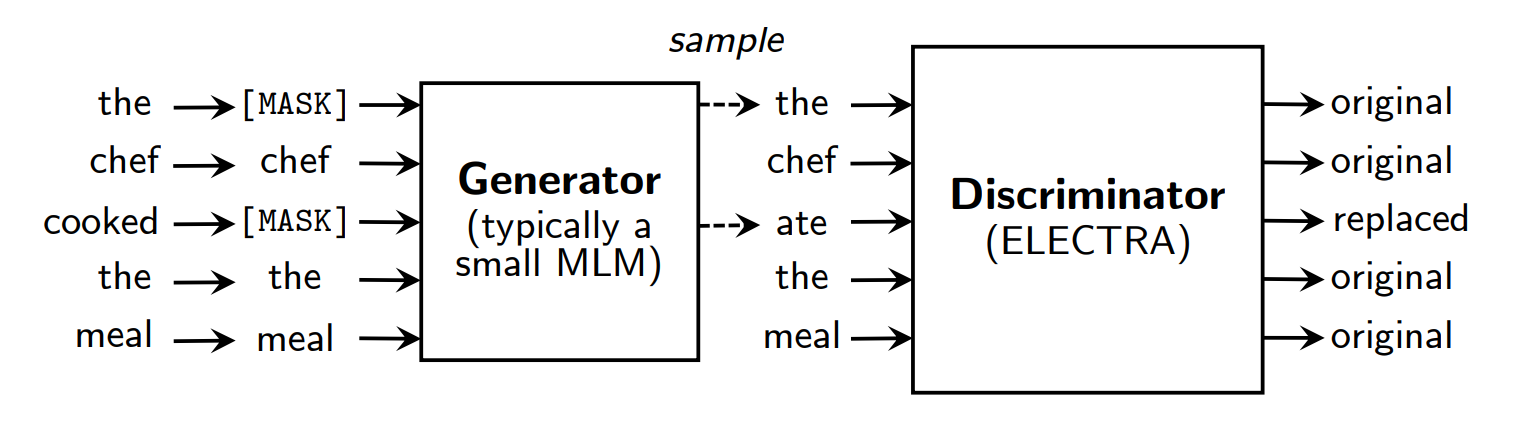
ELECTRA는 MLM task와 유사한 replaced token detection task로 학습합니다. BERT와 같이 먼저 입력 문장의 15%를 MASK token으로 바꿔줍니다. 그리고 Generator로 MASK token을 기존 token으로 예측하는 작업을 수행합니다. 당연히 잘 안 될 수도 있습니다. 그 후 Discriminator로 각각의 token이 기존 token과 같은지 예측합니다. Generator와 Discriminator의 Embedding Layer를 공유합니다. 참고로 Generatorlayer size는 Discriminator layer size의 1/4~1/2일 때 높은 성능을 보입니다.
SpanBERT
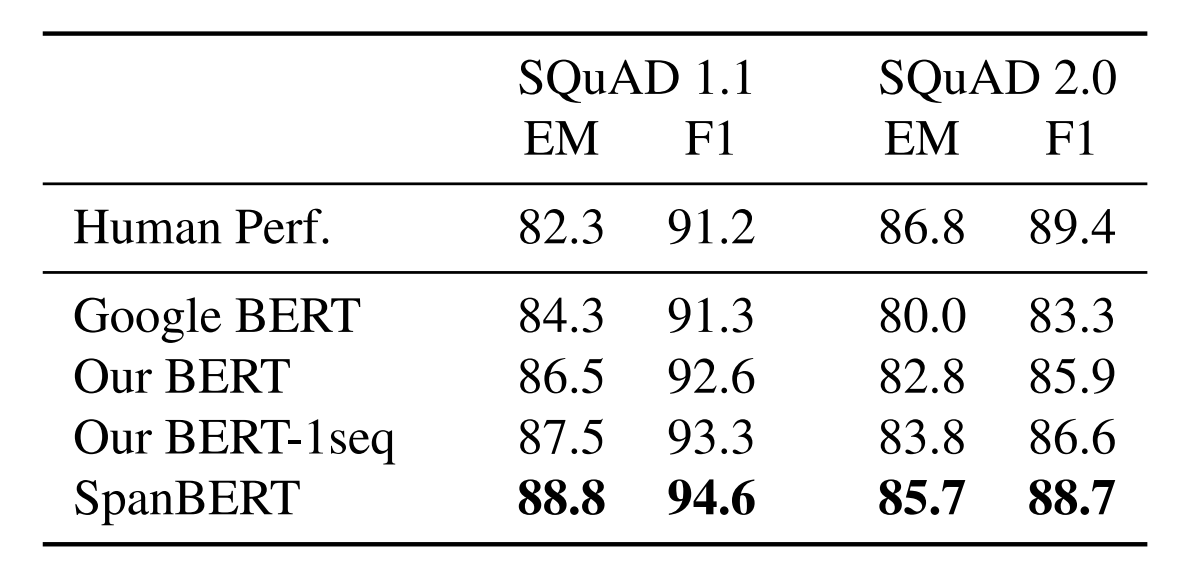
SpanBERT: Improving Pre-training by Representing and Predicting Spans 논문에서 나온 모델입니다. SpanBERT는 주로 Q&A take에 사용됩니다.
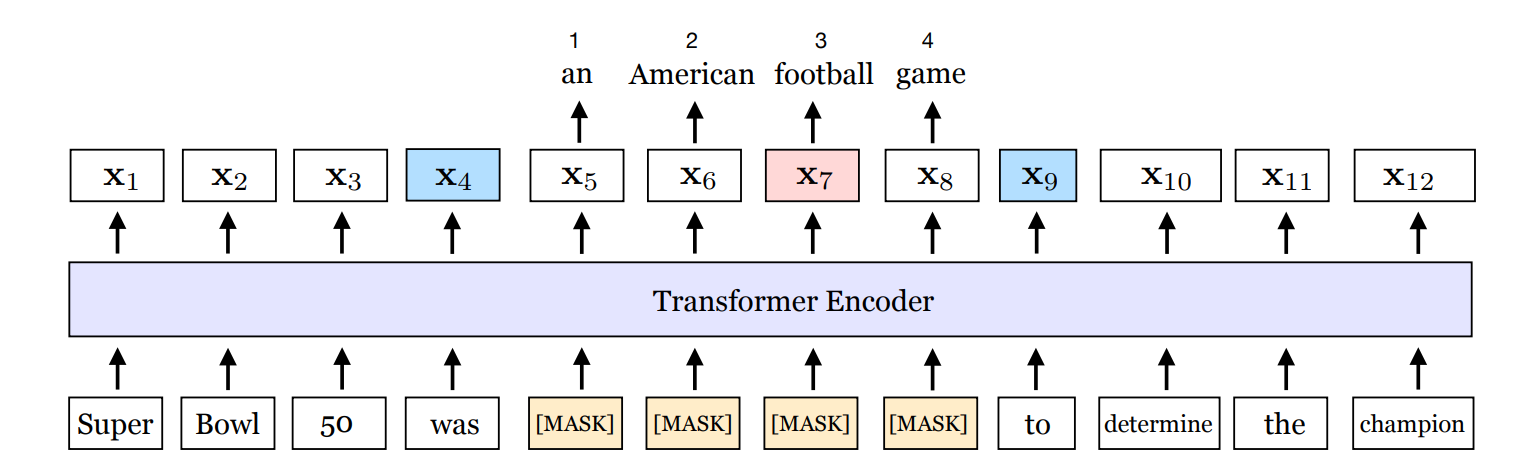
SpanBERT는 연속된 범위(span)를 랜덤으로 masking 합니다. SpanBERT는 MLM와 SBO로 학습합니다. SBO(span-boundary objective)는 span 경계의 token과 MASK token들의 position embedding을 아래 식에 넣어, mask 된 문장을 예측합니다.
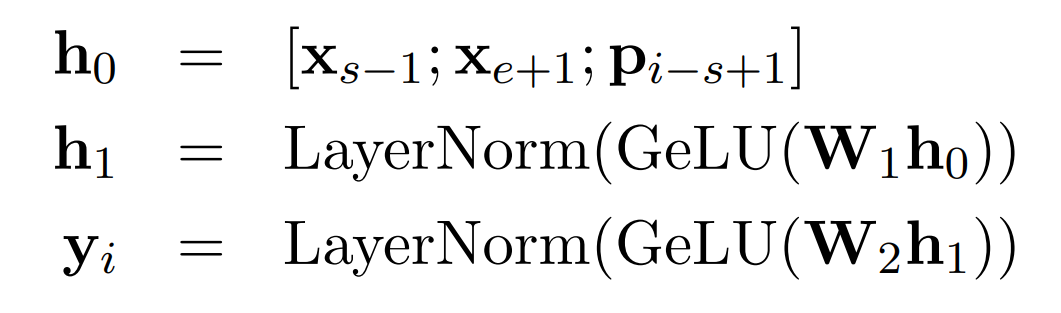
경계는 Figure 1에서 파란색 부분(Xs-1, Xe+1)입니다. position embedding은 경계 시작 - 현재 token의 위치(Pi-s+1)로 구합니다.
DistilBERT
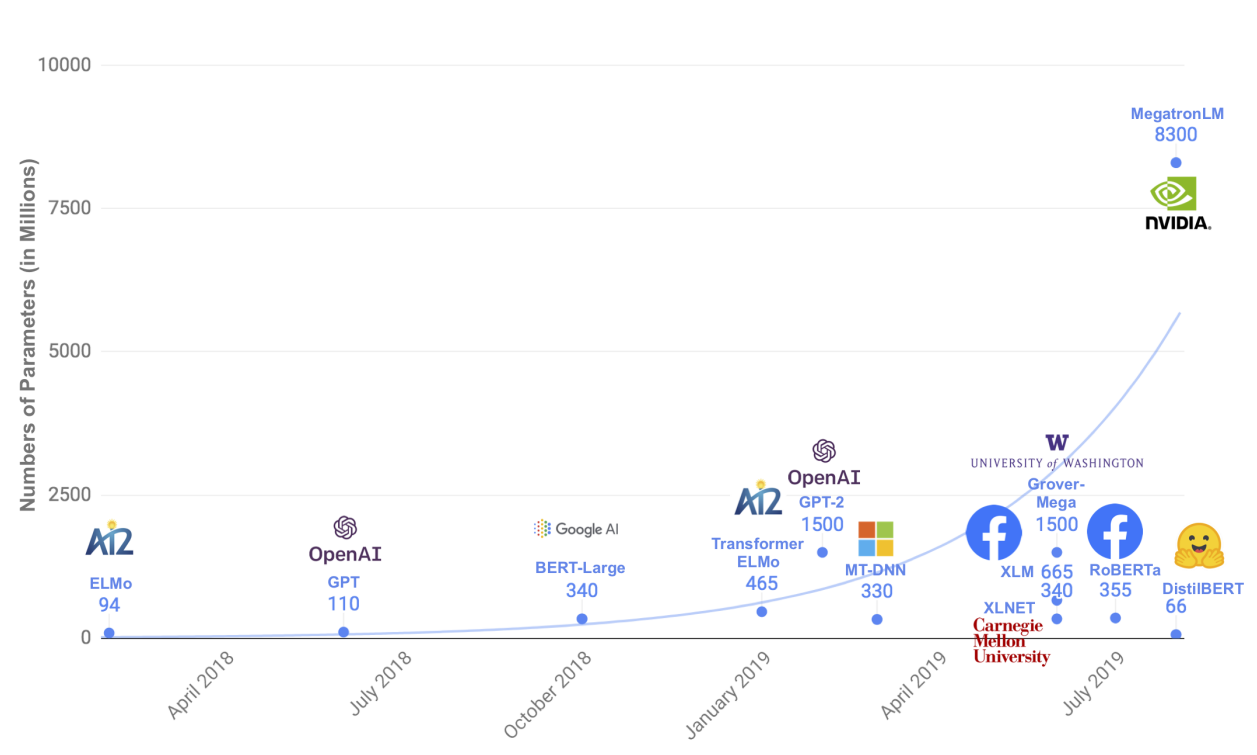
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter 논문에서 나온 모델입니다. DistilBERT는 Knowledge distillation로 model size를 줄이고 성능을 유지합니다.
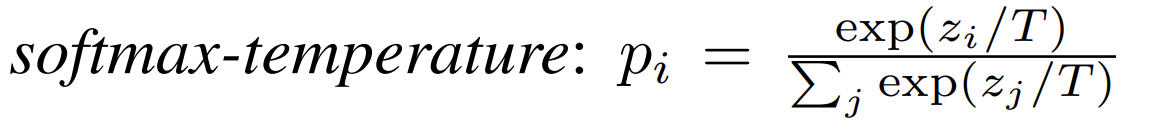
DistilBERT는 교사(대형) BERT에서 학생(소형) BERT로 Knowledge distillation을 진행합니다. MLM task만으로 학습을 진행합니다. 같은 문장을 입력하여, 교사 BERT와 학생 BERT로 MLM task를 진행합니다. MASK에 대한 예측 softmax 값을 softmax-temperature 수식으로 바꿔서 다양한 class에 대한 정보를 얻습니다. 그리고 학생 BERT 예측과 정답 간의 순수한 softmax 값을 얻습니다. 마지막으로 교사 BERT와 학생 BERT의 hidden states vectors로 cosine embedding loss를 구합니다. 이 3가지 loss를 최소화하는 방향으로 학습합니다.
TinyBERT
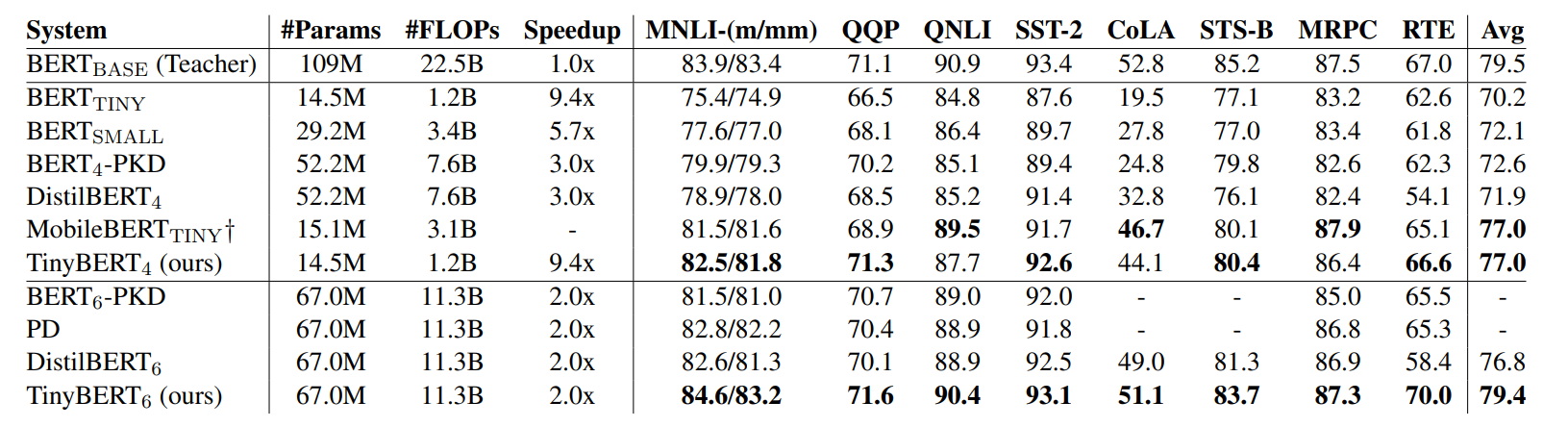
TinyBERT: Distilling BERT for Natural Language Understanding 논문에서 나온 모델입니다. TinyBERT는 DistilBERT의 응용 버전이라고 볼 수 있습니다.

TinyBERT는 교사 BERT의 여러 layer knowledge를 학생 BERT에 distillation 합니다. 먼저 Embedding Layer를 distillation 합니다. 교사 BERT Encoder의 Attention Matrices와 Hidden Startes도 distillation 합니다. 교사 BERT와 학생 BERT의 embedding dimension, hidden startes size가 다름으로, 학생 BERT 각각의 부분에 Wh를 곱해서 크기를 맞춰줍니다. 모두 MSE를 최소화하는 방향으로 학습합니다. 마지막으로 예측 값 softmax-temperature의 cross-entropy를 최소화하는 방향으로 학습합니다.
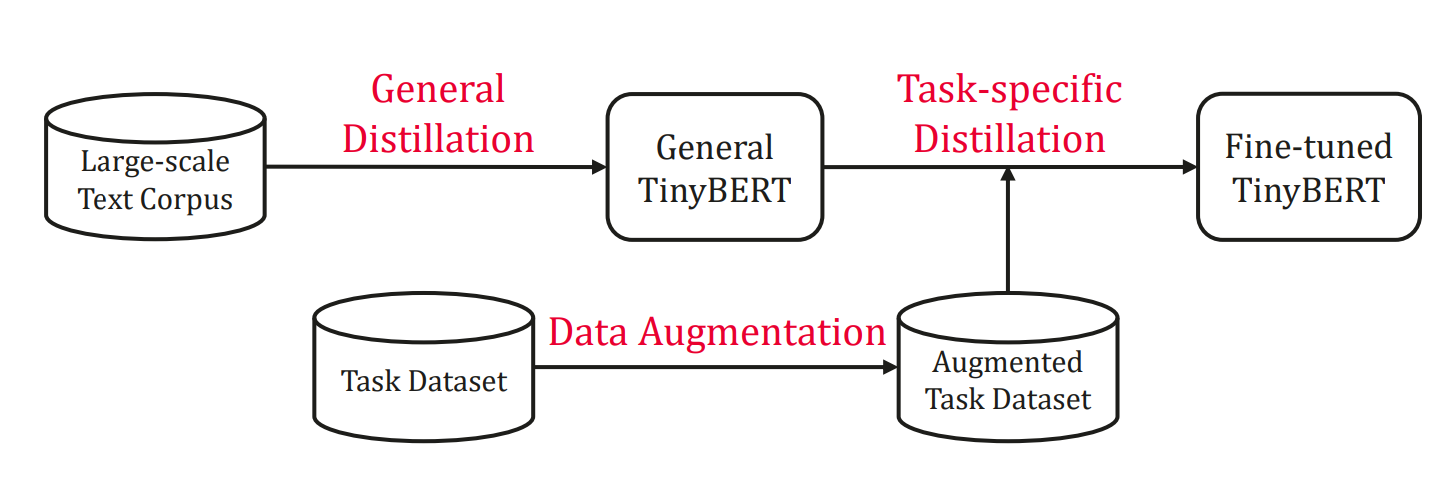
그리고 TinyBERT는 Task-specific(Fine-Tuning) distillation도 가능합니다. 다만 많은 데이터가 필요하여 Data Augmentation 과정이 필요합니다. Data Augmentation는 단일 단어의 경우, 교사 BERT로 Masking 후 예측 확률이 높은 K개의 단어를 저장합니다. 단일 단어가 아닌 경우, Glove embedding으로 가장 유사한 단어 K개를 저장합니다. 그리고 40% 확률로 단어를 바꿔줍니다.
Distilling BERT into BiLSTM
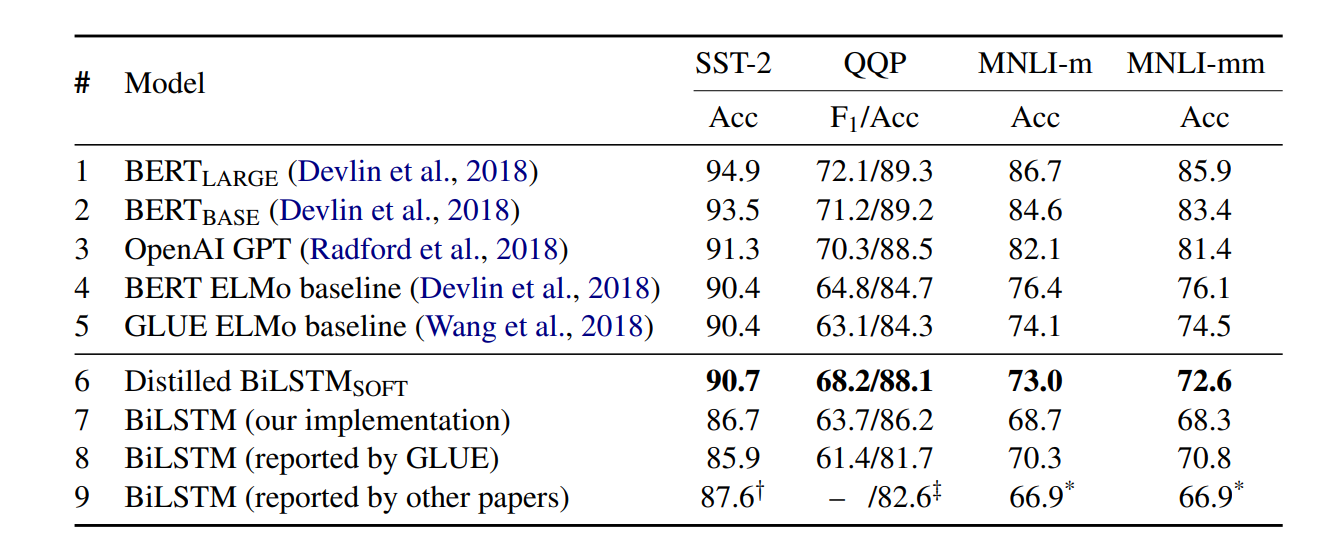
Distilling Task-Specific Knowledge from BERT into Simple Neural Networks 논문에서 Fine-Tuning된 BERT-large를 BiLSTM으로 Knowledge distillation 하여 모델의 크기를 크게 줄이는 것을 보여줍니다.
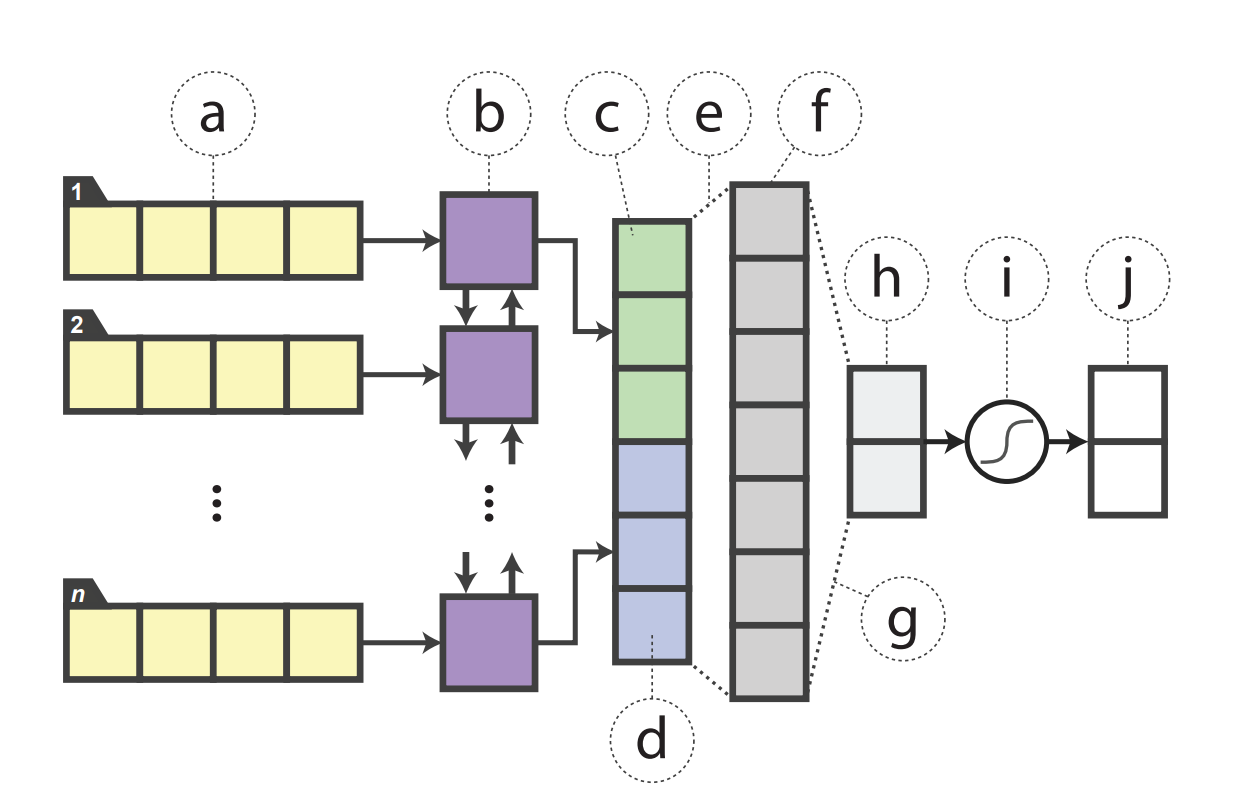
단일 문장 감정 분류 학습법을 알아보겠습니다. 먼저 문장의 embedding을 얻습니다. 이를 BiLSTM으로 backward, forward hidden states를 얻습니다. 이를 ReLU를 사용하는 fully-connected layer에 넣어서 logit 값을 얻습니다. 마지막으로 이를 Softmax에 넣어 긍부정 확률을 얻습니다.
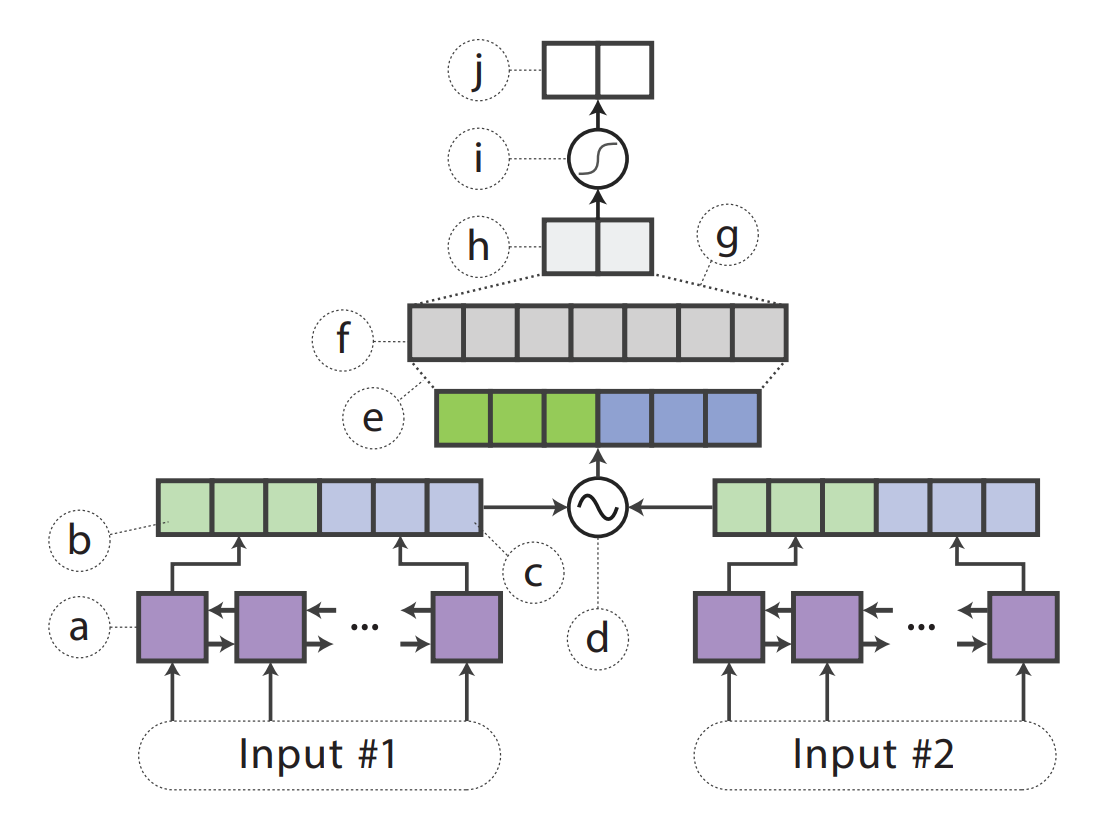
두 문장이 비슷한지 알아보는 모델을 학습하겠습니다. 두 문장의 embedding을 얻습니다. 가중치를 공유하는 siamese BiLSTM으로 backward and forward hidden states를 얻습니다. 첫 문장에서 얻은 vectors를 hs1, 두 번째는 hs2라고 하겠습니다. 이를 다음 수식으로 concatenate 합니다. [hs1, hs2, hs1 O hs2, |hs1 − hs2|] 여기서 O는 요소별 곱셈입니다. 이를 ReLU를 사용하는 fully-connected layer에 넣어서 logit 값을 얻습니다. 마지막으로 이를 Softmax에 넣어 유사도를 얻습니다.
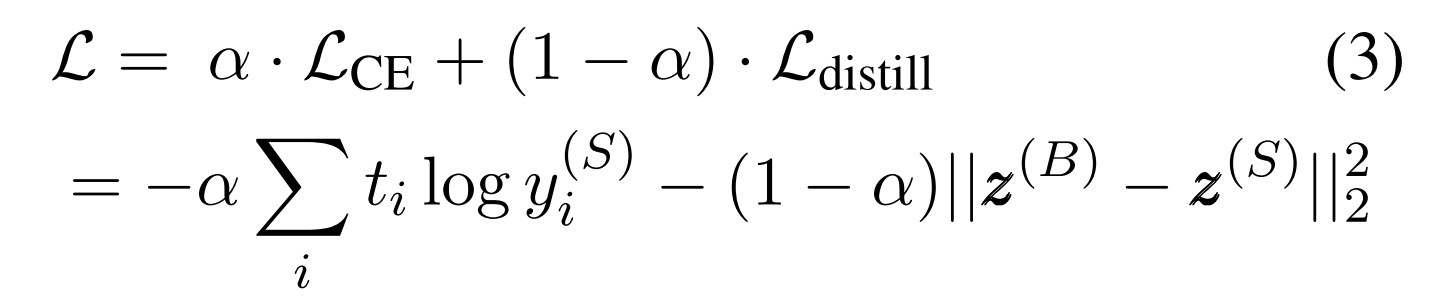
loss는 DistilBERT에서 배운 예측의 softmax-temperature를 MSE로, softmax를 cross entropy로 loss를 최소화하는 방향으로 학습합니다.

TinyBERT에서 배운 것과 같이 Fine-Tuning 된 BERT를 Knowledge distillation 하려면 많은 데이터가 필요합니다. 따라서 Data Augmentation 과정을 진행합니다. 문장을 입력받고, 각각의 단어에 대해 0~1 사이의 Xi를 만듭니다. 그리고 다음 과정을 적용하여 Data Augmentation과정을 진행합니다. Xi < Pmask 이면 masking 합니다. Pmask <= Xi < Pmask + Ppos이면 같은 품사의 다른 단어로 바꿉니다. Png확률로 n-gram sampling을 진행합니다. n은 1~5입니다.
BERTSUM
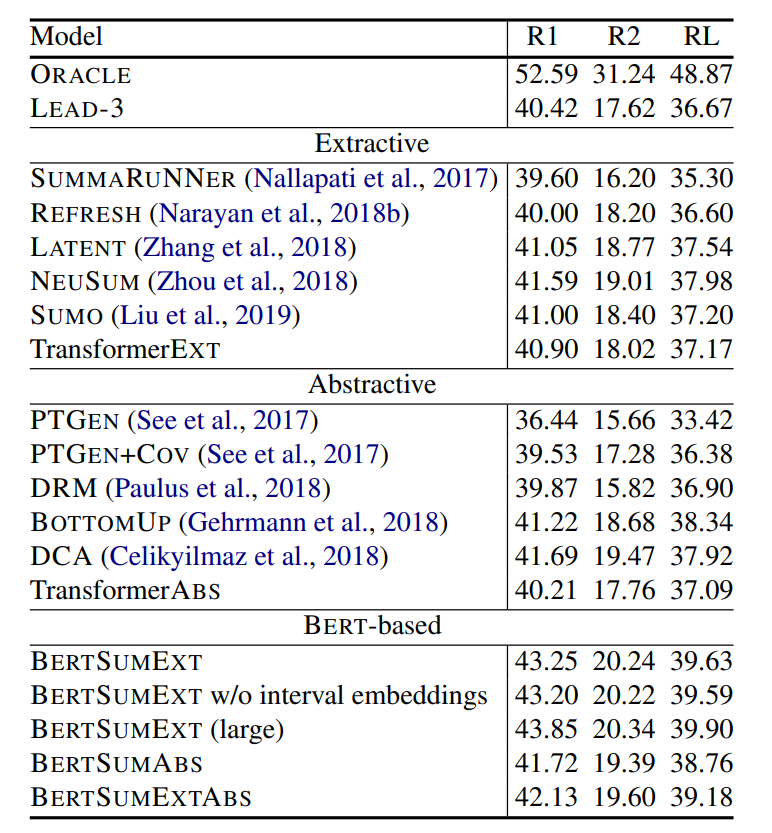
Text Summarization with Pretrained Encoders 논문에서 나온 모델입니다. BERT로 summarization task를 수행합니다. summarization 방법으로 Extractive summarization, Abstractive summarization 두 가지 방법이 있습니다. 일반 BERT는 문장 쌍을 입력받지만, BERTSUM은 여러 문장을 입력받습니다.
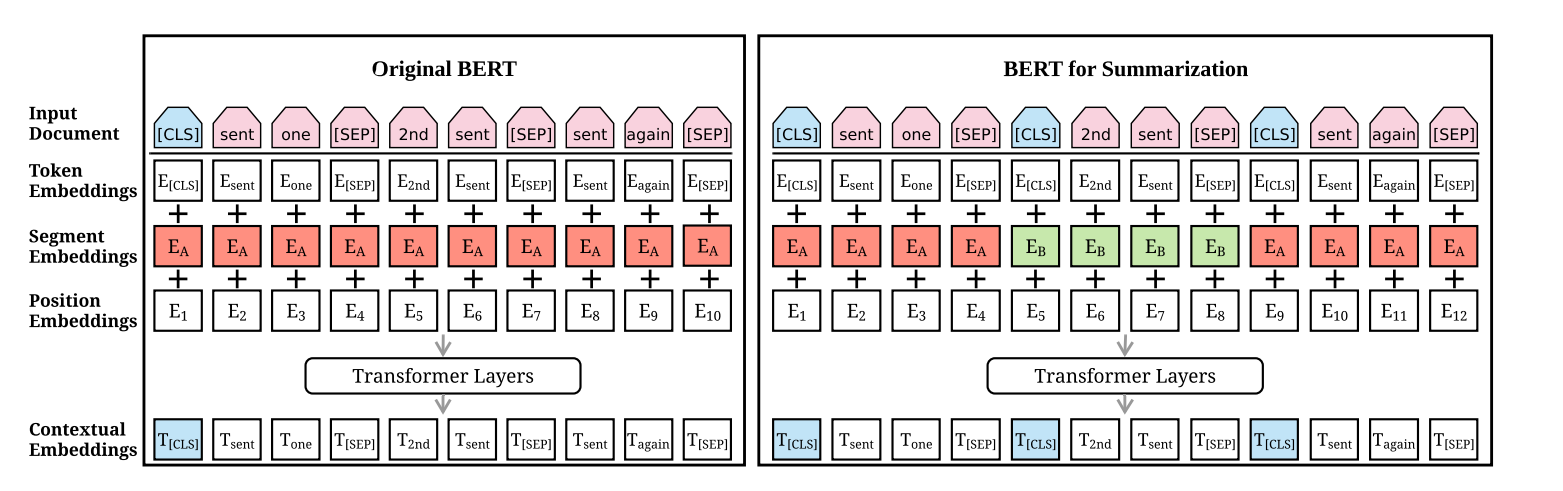
먼저 Extractive summarization는 각각의 문장을 삭제할지, 추출할지 결정합니다. 이를 위해서 input 데이터를 수정합니다. 각각의 문장 시작에 CLS token을 추가하고 끝에는 SEP token을 추가합니다. Segment Embedding은 문장의 순서가 짝수면 EA 홀수면 EB로 매핑합니다.
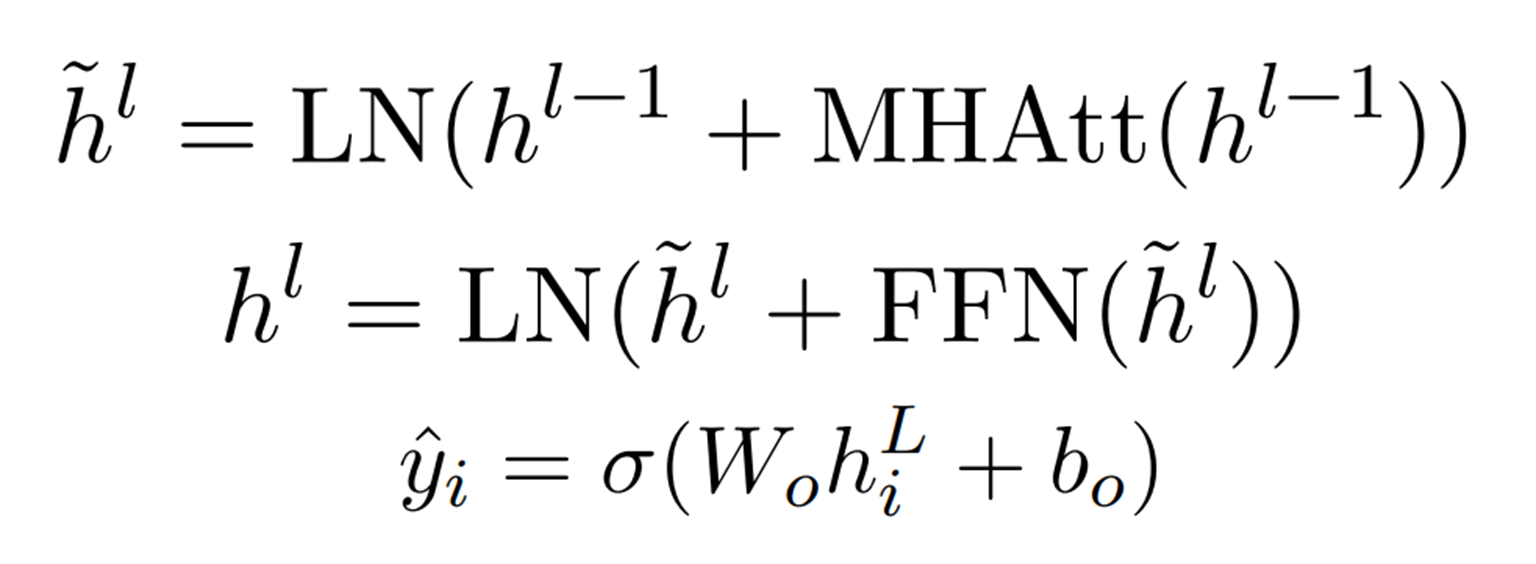
BERT 예측 값의 CLS token 부분을 이용하면, 간단하게 문장 요약을 할 수 있습니다. 해당 부분을 Sigmoid 분류기에 넣어서 문장의 추출 여부를 결정합니다. 더 복잡한 방법으로 BERT 예측 값을 2 layer transformer Encoder에 넣습니다. 결과(hiL)를 Sigmoid 분류기에 넣어서 문장의 추출 여부를 결정합니다. transformer가 아닌 LSTM으로도 만들 수 있습니다.

다음으로 Abstractive Summarization는 문장의 요약을 직접 작성합니다. 요약할 문장을 Extractive summarization로 pre-training 된 BERTSUM encoder에 넣어서 문장을 이해합니다. 이를 랜덤으로 초기화된 6 layer transformer decoder에 넣어서 요약된 문장을 생성합니다. 학습 시 encoder 보다 decoder의 높은 learning rates를 주어 학습합니다.
M-BERT
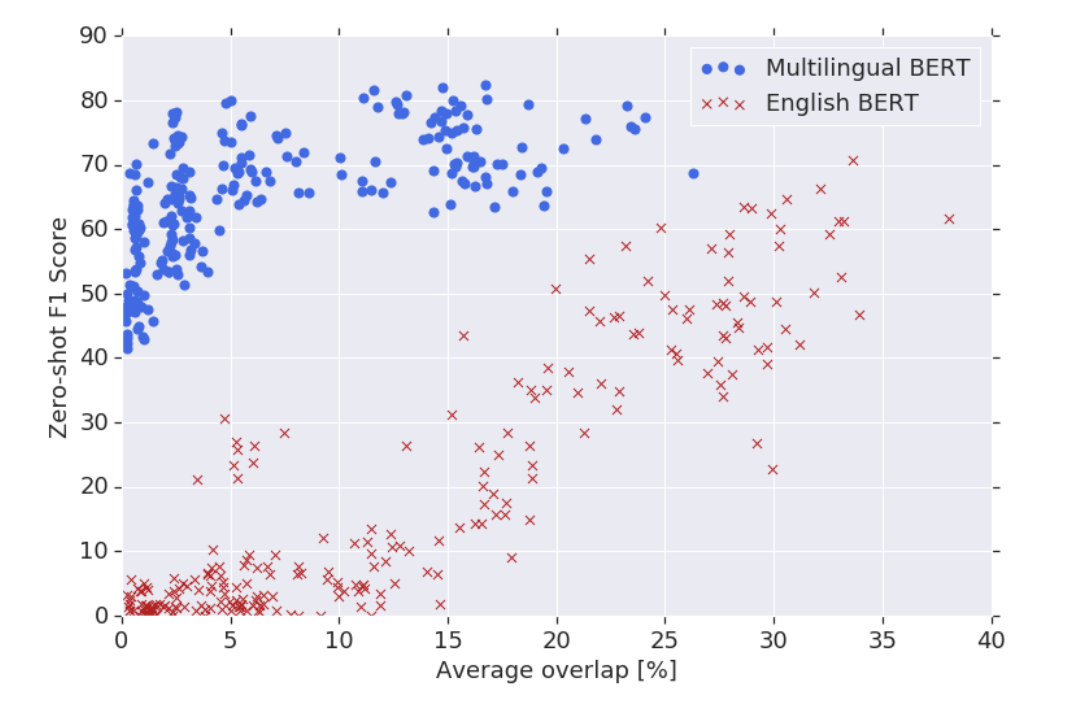
How multilingual is Multilingual BERT? 논문에서 나온 모델입니다. M-BERT는 다양한 언어로 BERT를 사용할 수 있습니다. M-BERT는 104개 언어의 Wikipedia 데이터로 MLM, NSP Task를 통해 학습합니다. M-BERT는 WordPice로 tokenization 합니다.
XLM
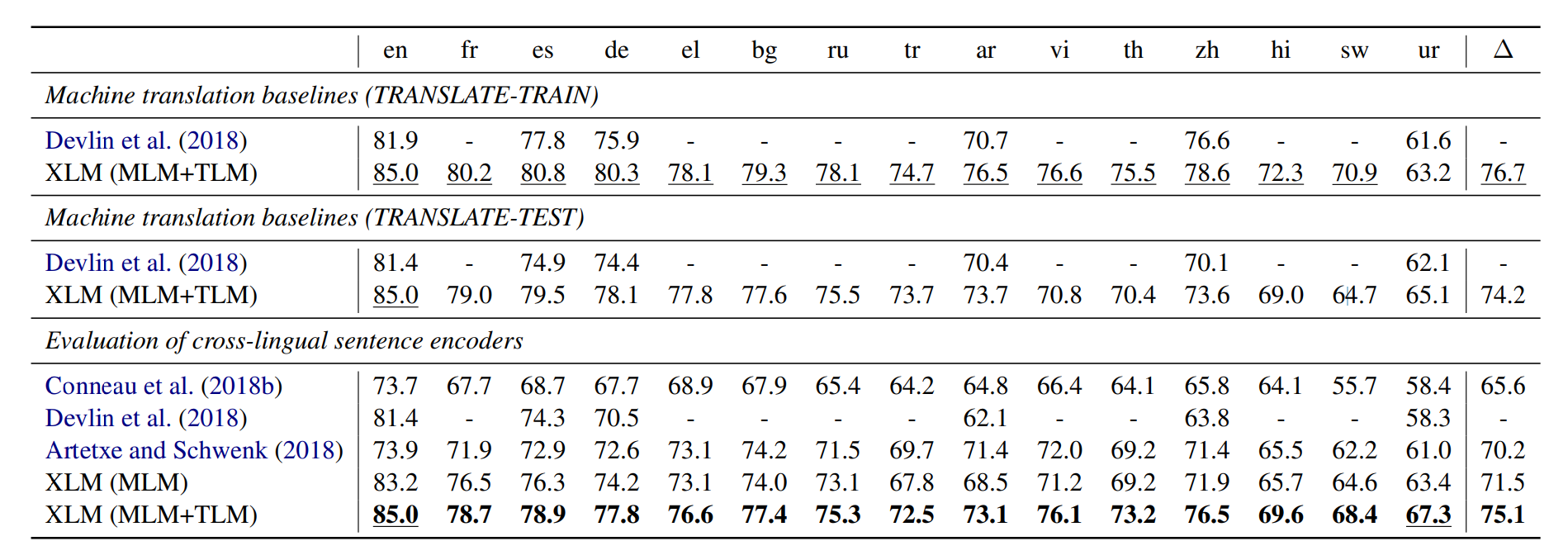
Cross-lingual Language Model Pretraining 논문에서 나온 모델입니다. XLM은 다양한 언어를 M-BERT보다 높은 성능으로 사용할 수 있습니다. XLM는 BPE를 tokenization로 사용하고 단일 언어 데이터는 Wikipedia에서 병렬 언어 데이터는 MultiUN, OPUS 등을 사용합니다. XLM는 CLM, MLM, TLM을 통해 학습합니다.
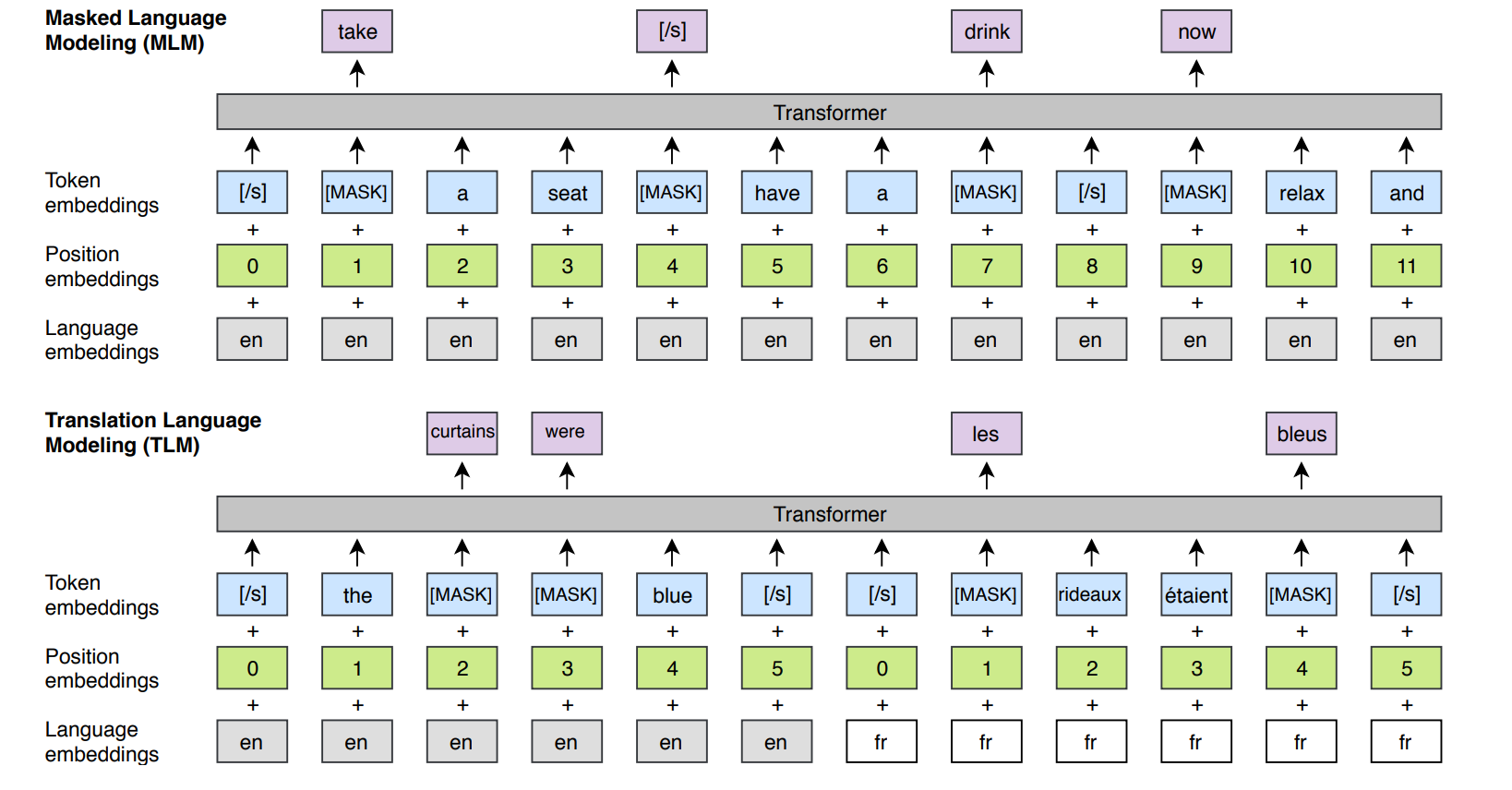
XLM은 기존 BERT와 다르게 문장을 구분하는데 Segmet Embedding이 아닌 언어를 구분하는 Language Embedding을 사용합니다. 그리고 문장의 시작과 끝에 [/S] token을 넣어서 문장을 구분합니다. 마지막으로 문장 쌍이 아닌 임의의 수의 문장을 넣습니다.
CLM(caual language modeling)은 일반적인 lm task입니다. 이전 단어를 기반으로 다음 단어를 예측합니다. MLM task에서 자주 등장하는 단어와 가끔 등장하는 단어의 균형을 맞추기 위해, 가중치를 sqrt(1/빈도수)로 다향 분포에 따른 token sampling을 진행합니다. 이후 MLM과정은 같습니다. TLM(translation language modelling)은 언어가 다른지만 동일한 의미의 두 문장에 대해서, MLM 테스크를 수행합니다. 이때 문장은 언어별로 별도의 Position Embedding을 사용합니다.
XLM-R
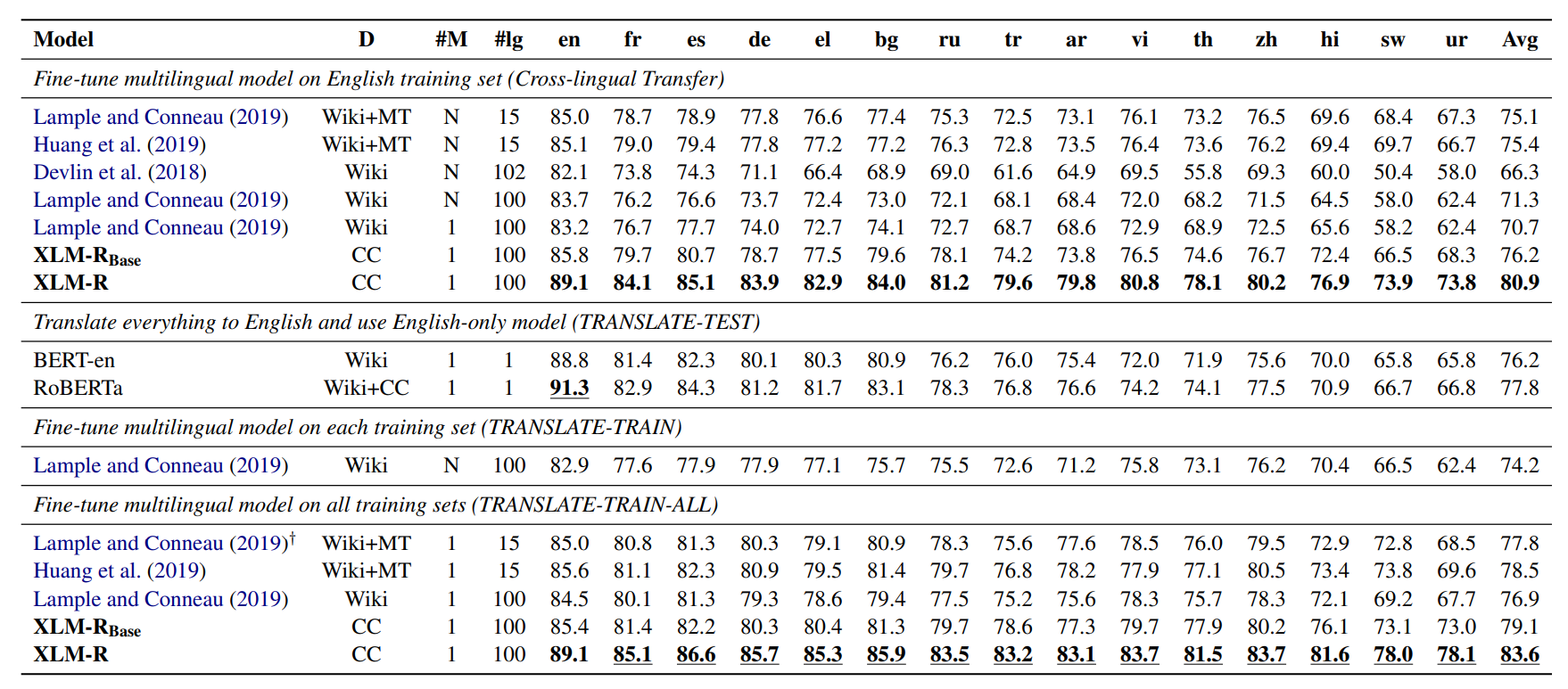
Unsupervised Cross-lingual Representation Learning at Scale 논문에서 나온 모델입니다. XLM-R은 XLM을 RoBERTa로 학습시키는 등 기술을 보완하여 더 높은 성능을 보입니다.
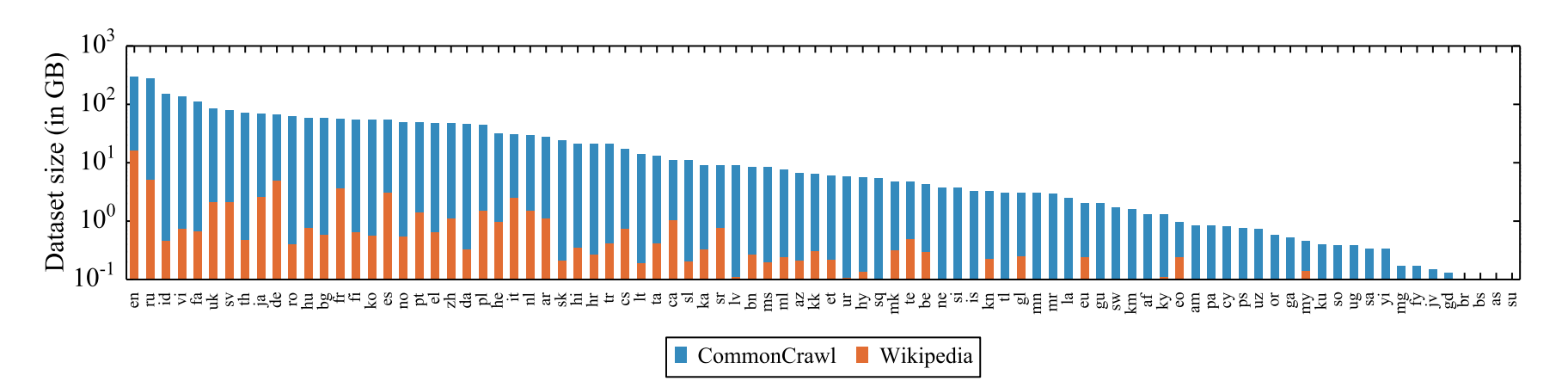
XLM-R은 오직 MLM task로만 학습합니다. Common Crawl과 Wikipedia를 통해서 학습을 진행합니다. XLM-R은 SentencePice를 이용하여 tokenization 합니다.
Sentence-BERT
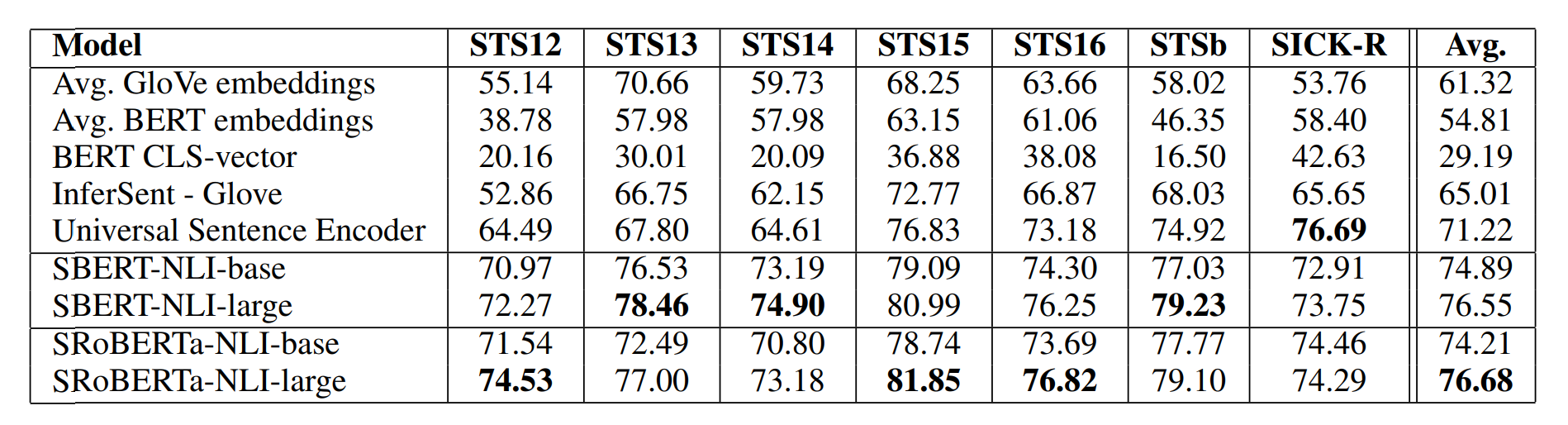
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks 논문에서 나온 모델입니다. Sentence-BERT는 BERT나 RoBERTa를 Find-Tuning 하여, 문장의 표현을 빠르고 정확하게 얻을 수 있습니다.
BERT는 문장의 표현을 CLS token으로 얻습니다. Sentence-BERT는 문장의 표현을 얻기 위해, BERT의 표현을 모두 pooling 합니다. 보통 mean pooling을 사용합니다. Sentence-BERT는 문장 쌍을 입력하는 task에서 Siamese Network를 사용합니다. Triplet Loss를 사용하는 task에서는 Triplet Network를 사용합니다.
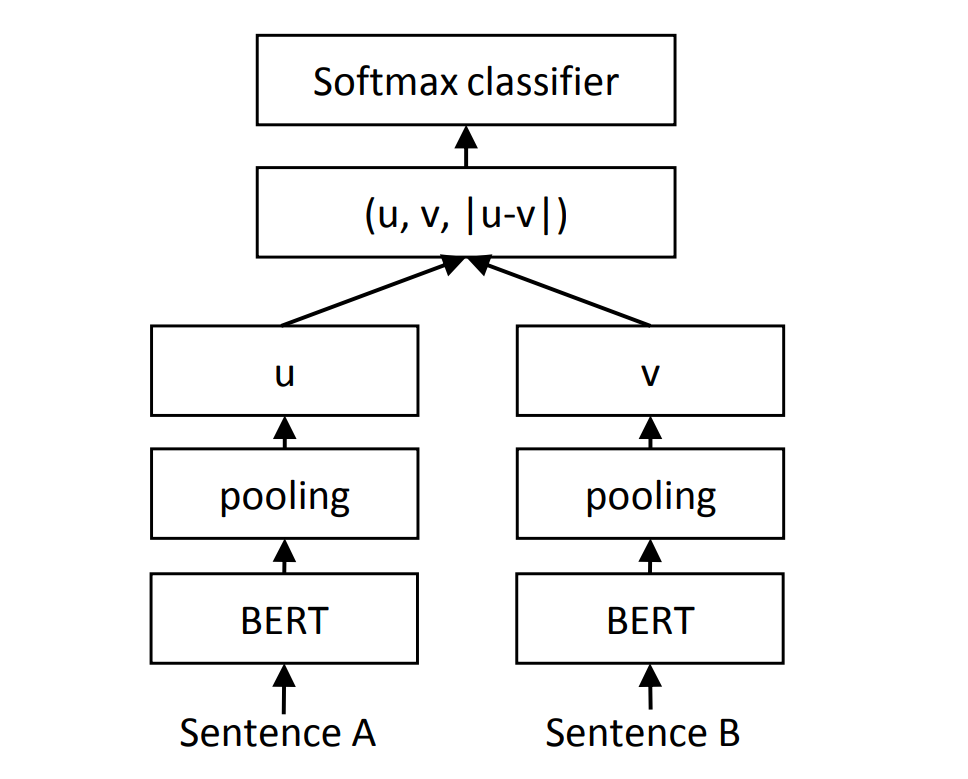
먼저 Sentence-BERT로 문장 이 유사한지 유사하지 않는지 분류하는 task를 학습하겠습니다. 두 문장을 BERT에 넣고 pooling 하여 u와 v를 얻습니다. softmax(Wt(u, v, |u − v|))로 문장의 유사도를 얻습니다. 이를 cross-entropy loss를 최소화하는 방향으로 W를 업데이트하여 학습합니다.
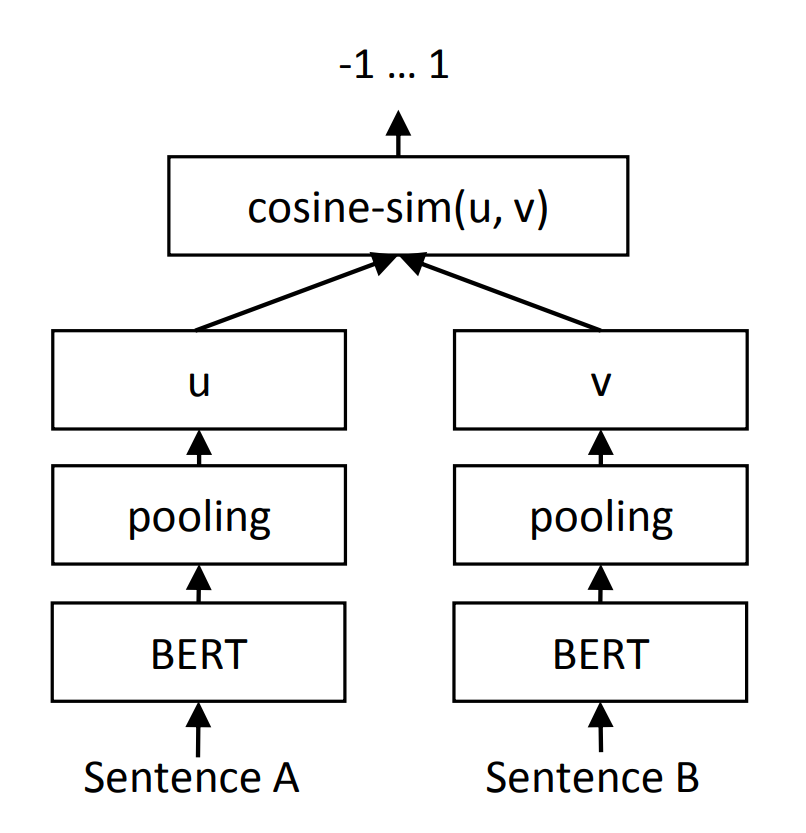
다음으로 Sentence-BERT로 문장 쌍의 유사도 구하는 task를 학습하겠습니다. 위 task와 같이 두 문장의 표현 u, v를 얻고 cosinesimilarity로 유사도를 구합니다. MSE loss를 최소화하는 방향으로 학습합니다.
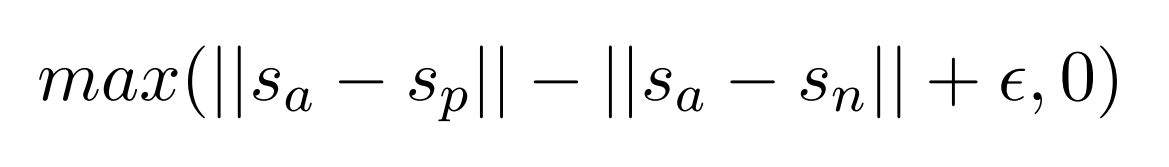
마지막으로 Triplet loss 최소화하는 task를 학습하겠습니다. 기준 문장 Sa, 긍정(함의) 문장 Sp, 부정(모순) 문장 Sn 3가지 문장이 있습니다. 위 task와 같이 문장의 표현 Sa, Sp, Sn을 얻습니다. Sa와 Sp의 유사도를 높이고, Sa와 Sn의 유사도를 낮춰야 됩니다. Sa - Sp의 Euclidean distance가 Sa - Sn의 Euclidean distance보다 작도록 계산합니다. margin을 통해 Sa에서 Sp가 Sn보다 적어도 margin보다 가깝게 보장합니다.
Multilingual Sentence-BERT
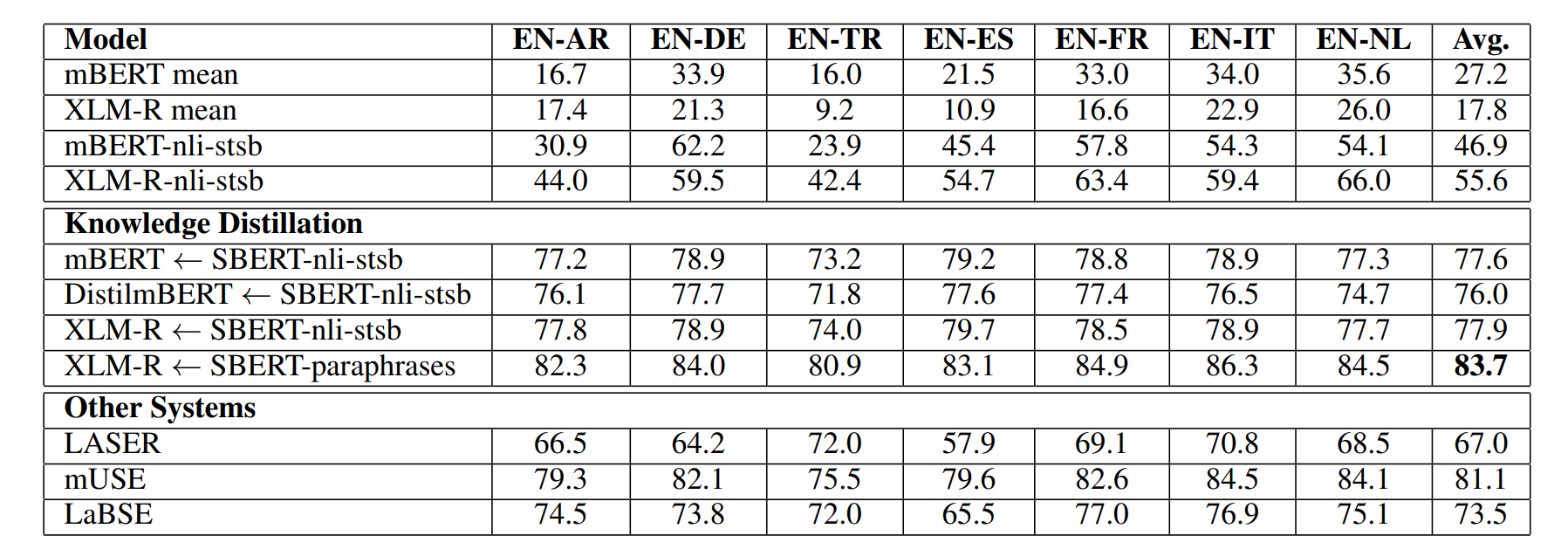
Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation 논문에서 나온 모델입니다. 다양한 언어로 Sentence-BERT를 이용할 수 있게 학습합니다. XLM-R을 학생 BERT로 Sentence-BERT를 교사 BERT로 Knowledge distillation 합니다.
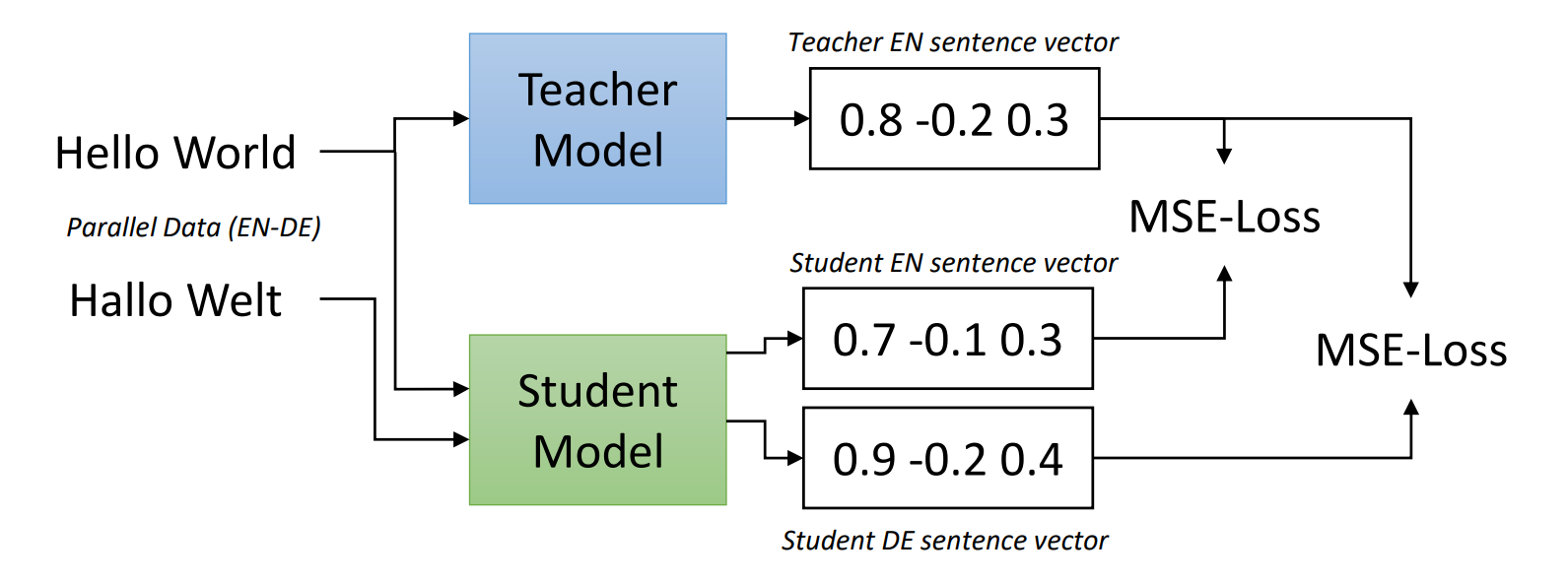
동일한 의미의 영어 문장과 독일어 문장이 있습니다. 교사(Sentence-BERT)는 영어 문장에 대해서만, 학생(XLM-R)은 영어, 독일어 각각 문장의 표현을 얻습니다. Figure 1과 같이, 학생의 두 표현과 교사의 표현에 대한 MSE loss를 얻습니다. 두 loss의 합을 최소화하는 방향으로 학습합니다.
ClinicalBERT
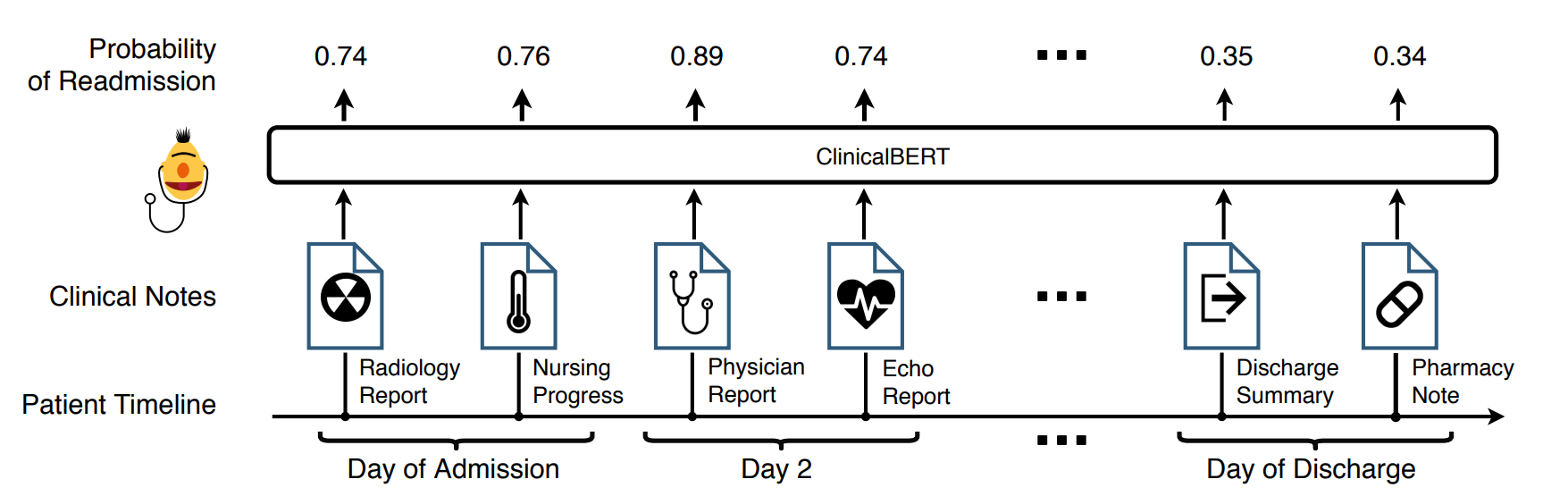
ClinicalBERT: Modeling Clinical Notes and Predicting Hospital Readmission 논문에서 나온 모델입니다. ClinicalBERT는 임상(의료) 데이터로 학습한 BERT입니다. Pre-training과정은 BERT와 동일합니다. 예측, 입원 기간, 사망 위험 추정, 진단 예측 등 다양한 task로 Find-Tuning 할 수 있습니다.
재입원 확률 예측 task를 find-tuning 해보려고 합니다. 문제는 BERT의 최대 token 길이는 512입니다. 환자의 임상 기록은 이보다 훨씬 많은 token을 가질 가능성이 높습니다. 그렇다면 임상 데이터를 여러 개의 subsequence로 분할합니다. 모든 subsequence를 model의 넣어 예측 값을 받습니다. 그리고 위 수식에 맞춰 재입원 확률을 계산합니다.
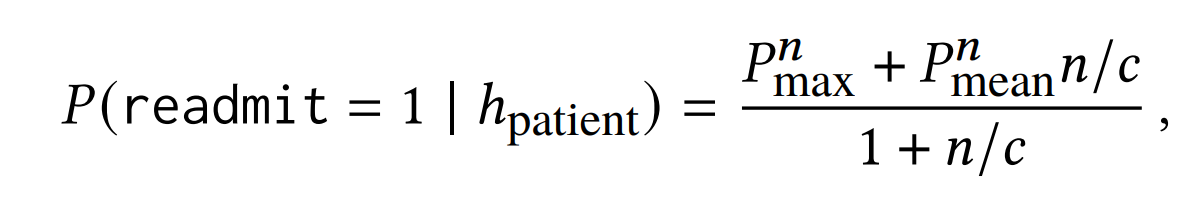
n은 subsequence의 수입니다. Pnmax은 예측값 중 최댓값입니다. Pnmaen은 예측값 평균입니다. c는 scaling값입니다. subsequence에서 재입원 예측과 관련이 없는 내용들이 많을 수 있습니다. 따라서 subsequence 중에 가장 확률이 높은 Pmax를 사용합니다. 그러나 subsequence에 nosie가 포함되어 있을 수 있고, Pmax가 nosie 값일 수도 있습니다. 이를 방지하기 위해서 Pmean도 사용합니다. subsequence 수가 많을수록 nosie가 많을 수도 있으니, Pmean에 n을 곱해줍니다. Pmean 값에 과하게 의존하지 않게, c를 나눠줍니다. 마지막으로 normalizing을 위해서, 1 + n/c를 나눠줍니다.
BART
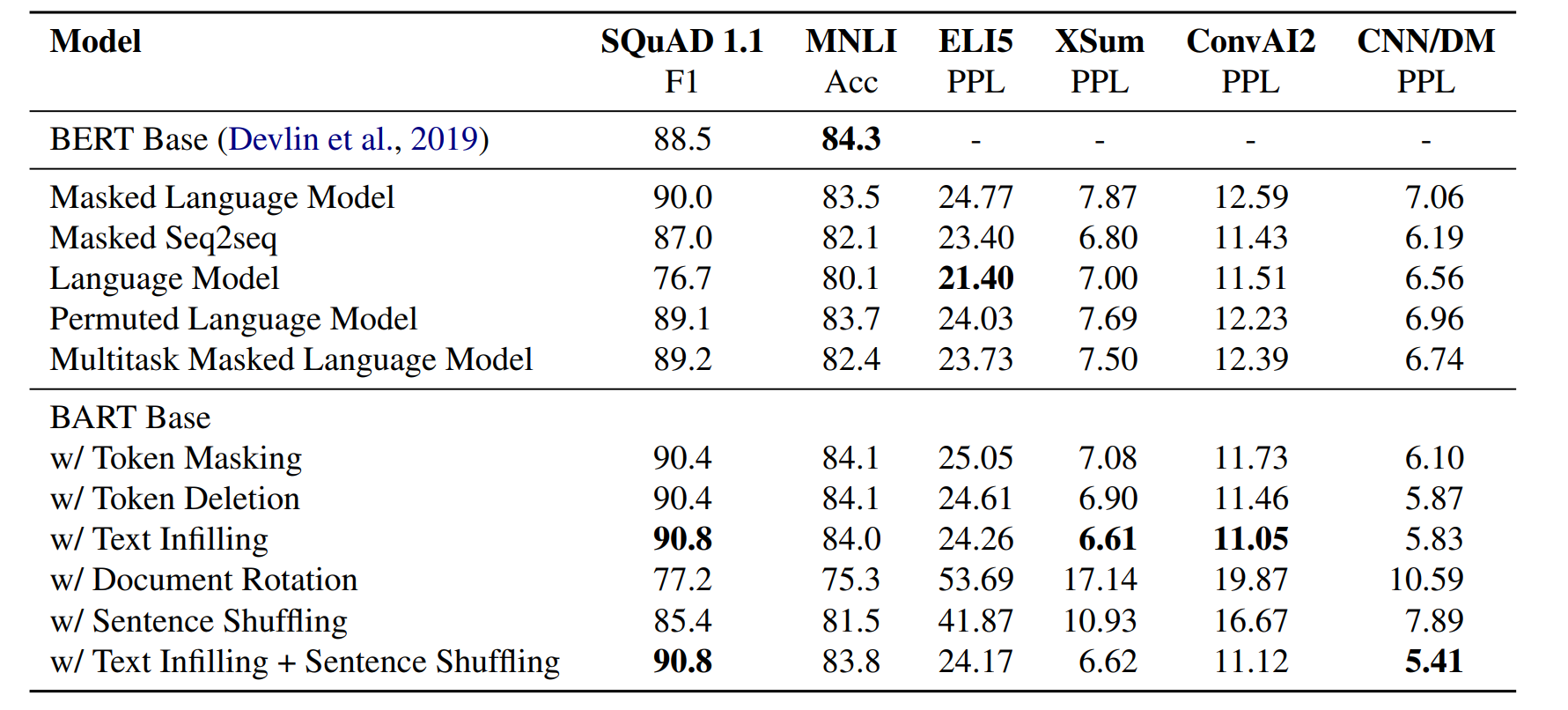
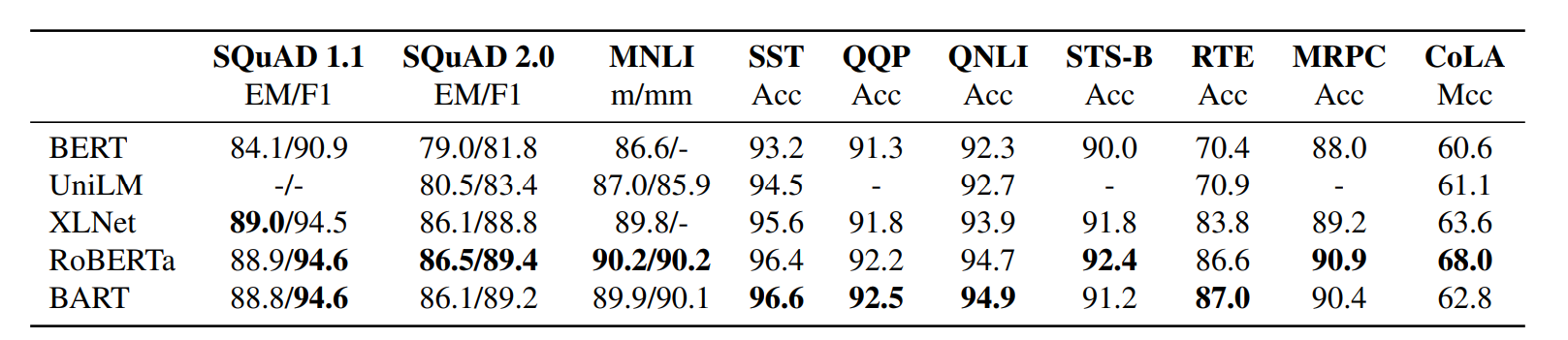
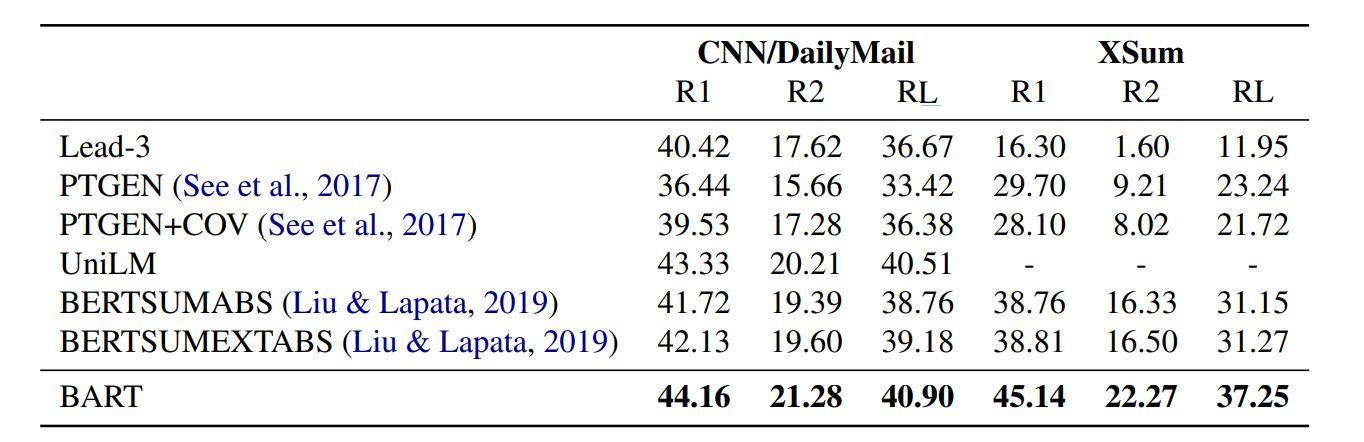
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension 논문에서 나온 모델입니다. BART는 손상된 문장을 입력하고 이를 복구하여 학습합니다.
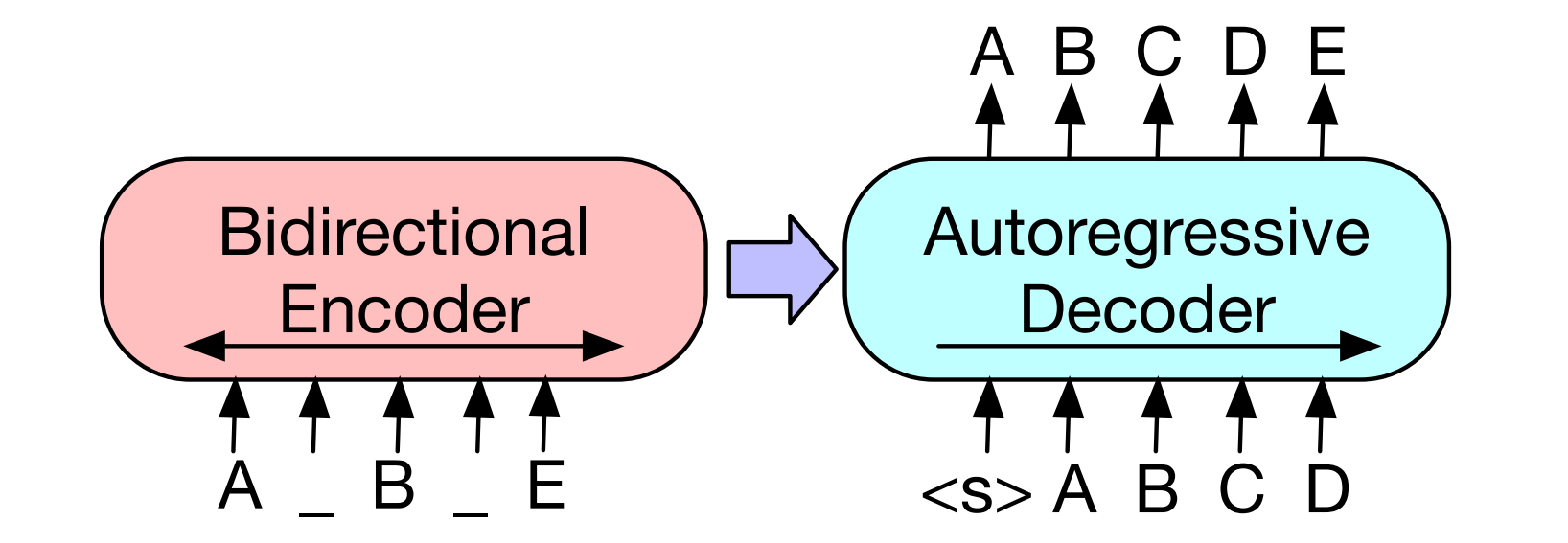
BART는 encoder와 decoder를 가진 transformer 모델입니다. 손상된 문장을 encoder에 입력하여 문장의 표현을 학습하고, 그 표현을 decoder로 보냅니다. decoder의 목표는 encoder가 생성한 표현을 가져와, 손상되지 않은 원본 문장을 생성하는 것입니다. BART는 원본 문장과 decoder가 생성한 문장 사이의 cross-entropy를 최소화하는 방향으로 학습합니다.
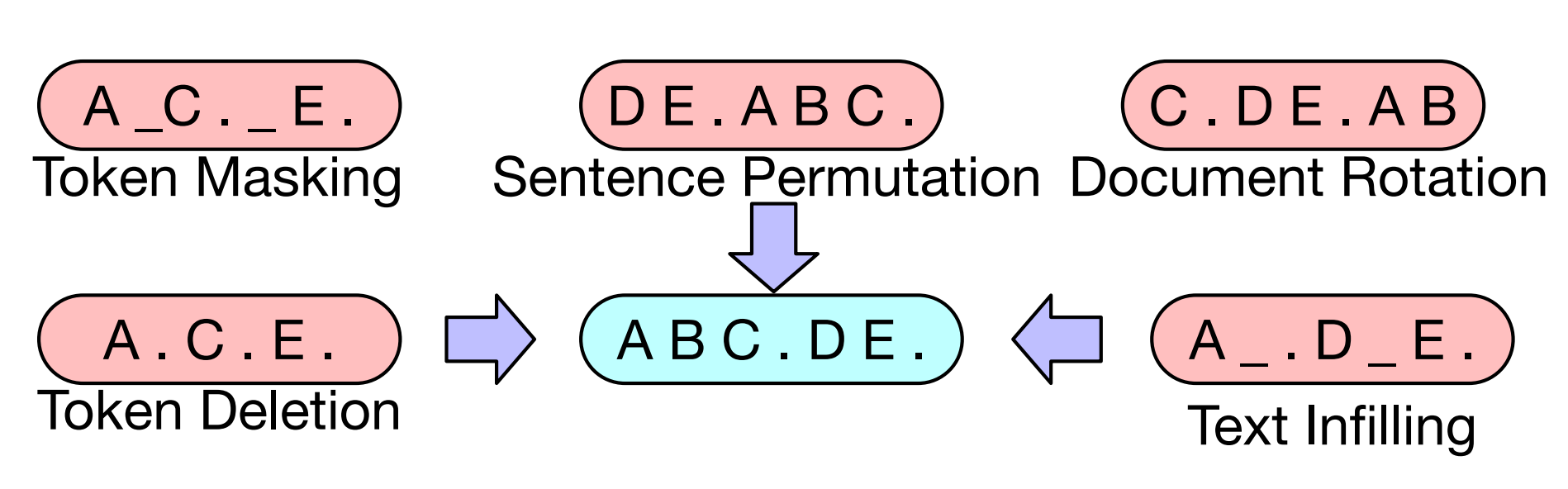
입력 문장을 손상시키는 여러 기술이 있습니다. 위에 Table 1에서 각각의 손상을 복구하는 방식별 성능이 나와있습니다.
- token masking은 BERT와 랜덤으로 token을 masking 합니다.
- token deletion는 랜덤으로 token을 삭제합니다.
- text infilling은 lambda가 3인 Poisson distribution로 token의 span(구간)을 구합니다. 이를 하나의 [MASK] token으로 바꿉니다.
- sentence permutation은 마침표(.) 기준으로 문장을 분리하고, 순서를 랜덤으로 섞습니다.
- document rotation은 랜덤으로 하나의 token을 정합니다. 해당 token으로 문장을 시작하고, 이전 token들을 뒤에 붙여줍니다.
Reference
- 구글 BERT의 정석
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS
- RoBERTa: A Robustly Optimized BERT Pretraining Approach
- ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS
- SpanBERT: Improving Pre-training by Representing and Predicting Spans
- DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
- TinyBERT: Distilling BERT for Natural Language Understanding
- Distilling Task-Specific Knowledge from BERT into Simple Neural Networks
- Text Summarization with Pretrained Encoders
- How multilingual is Multilingual BERT?
- Cross-lingual Language Model Pretraining
- Unsupervised Cross-lingual Representation Learning at Scale
- Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
- Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation
- ClinicalBERT: Modeling Clinical Notes and Predicting Hospital Readmission
- BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension



