ViT(Vision Transformer) 논문 리뷰를 해보겠습니다. Transformer는 NLP 테스크에서 Bert, GPT-3 등 기반 알고리즘으로 유명하죠. 이런 Transformer 알고리즘을 Vision 분야에서 사용합니다.
시작하기 앞서서 Transformer에 대해서 모르시는 분들은 아래 글을 읽어보시길 바랍니다. 이 글은 독자가 Transformer를 알고 있다는 가정을 하고, 작성했습니다.
ATTENTION IS ALL YOU NEED 논문 리뷰
RNN이나 CNN이 아닌 새로운 구조를 개척한 Attention Is All You Need을 리뷰를 해보겠다. 특이한 구조를 가지고 있다. 한국어 리뷰1, 한국어 리뷰2, 논문을 참고하자. ABSTRACT sequence transduction models..
hipgyung.tistory.com

흥미롭게 ViT가 아직도 CIFAR-10에서 SOTA를 차지하고 있습니다.
생각해보면 신기하지 않나요? 해당 테스크와 유사한 데이터를 Pre-Training을 하고 원하는 테스크의 데이터로 Fine-Tuning을 하여, 성능을 높이는 것은 Vision 분야에서 시작됐습니다. 해당 용어가 익숙하지 않다면, Transfer Learning(전이 학습)을 생각해주시면 됩니다. 해당 NLP 분야에서 해당 개념을 가져와서 LM을 학습했죠.
이제는 반대로 NLP 분야의 Transformer을 이용해서 Vision 분야에서 SOAT를 찍었습니다. 대단한 발전입니다. 뿐만 아니라, Transformer는 오디오, 추천 시스템 등에도 사용됩니다. 나중에는 딥러닝에서 분야를 나누는 게, 무의미해지지 않을까요?
이 블로그 리뷰는 논문을 가볍게 정리한 내용이니, 논문을 직접 보시는 게, 가장 좋습니다!
ViT의 특징
시작하기 전에 몇가지 정보를 보고 시작합시다.
- 기존 CNN 기반 SOTA 모델보다, 성능이 좋다. 거기다 Fine-Tuning 과정에서 적은 리소스로도 더 좋은 성능을 보여준다.
- 기존 Transformer 모델처럼 Parameter에 한계가 아직 없다. 더 많은 데이터와 더 많은 Parameter로 더 좋은 성능을 보여줄 수 있다.
- CNN, RNN과 다르게, 공간에 대한 bias가 없다. 따라서 많은 사전 데이터 학습이 필요하다.
- 많은 데이터를 사전 학습 해야 된다. 적은 데이터로 사전 학습 시, 성능이 나빠진다.
논문 리뷰 시작

Figure 1을 해석해보면, 모델에 대한 정보를 알 수 있습니다. 이미지를 텍스트 sequence처럼 사용하는 구조를 가지고 왔습니다. 먼저, 이미지를 고정된 크기의 patch로 나눠줍니다. 각각의 patch를 linearly embedding하고 position embedding을 하여, Transformer 인코더에 Input 값으로 넣습니다.
이미지를 나눈 후에, 일반적인 Transformer Input 값 처럼 바꾸네요. 거기에 classification token을 더해줍니다. 이미지를 Classification하기 위해서, 어떤 이미지인지, 알려주는 과정을 추가한 것입니다. 해당 정보를 이용해서 이미지 Class를 예측합니다.
쉽게 이해를 해볼까요? 이미지를 고정된 크기로 짤라서, Transformer의 Input을 넣어서 Transformer를 학습합니다. 아이디어가 직관적으로 이해되는 좋은 논문 같습니다. 동작 방식을 애니메이션으로 봐보죠.
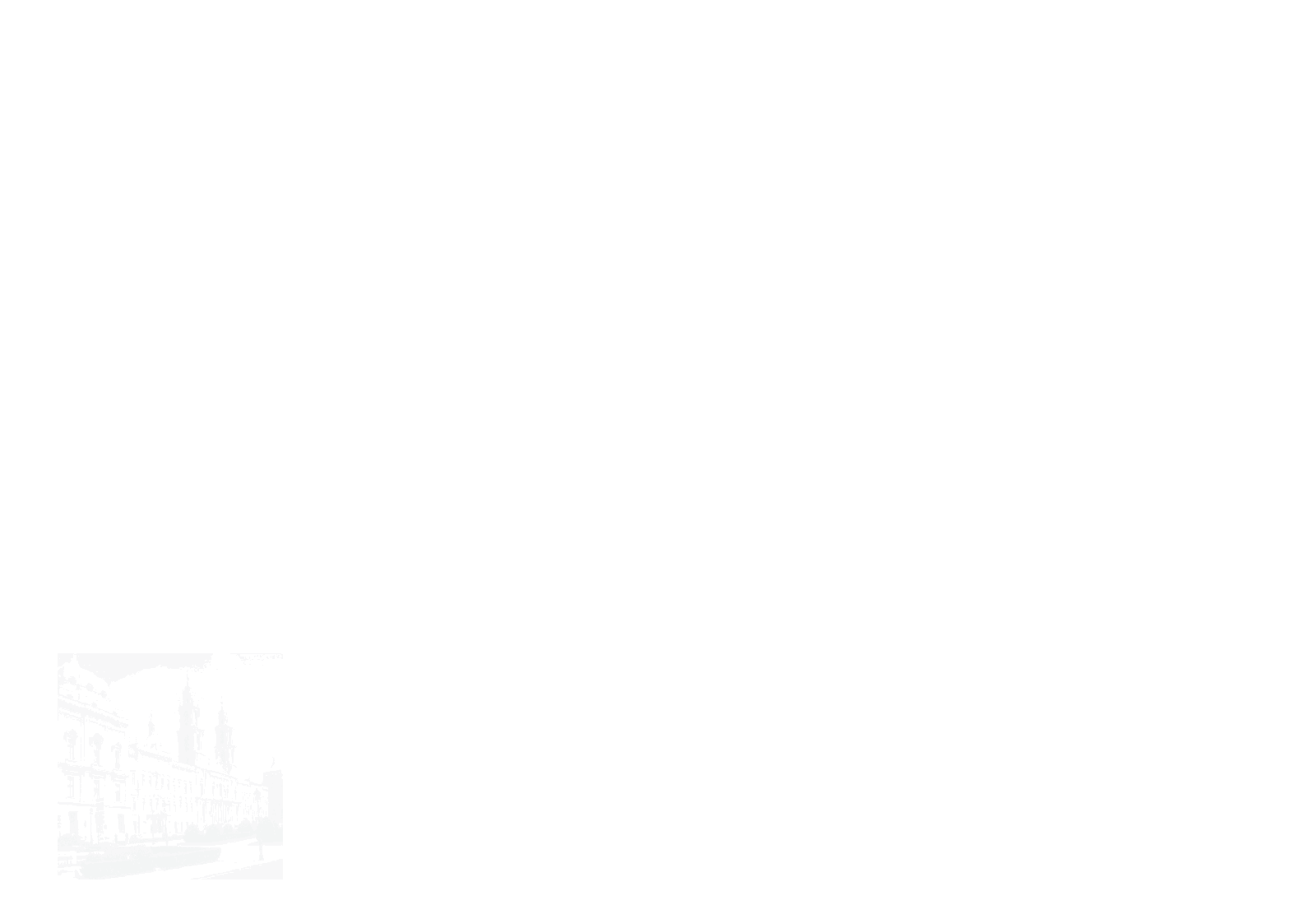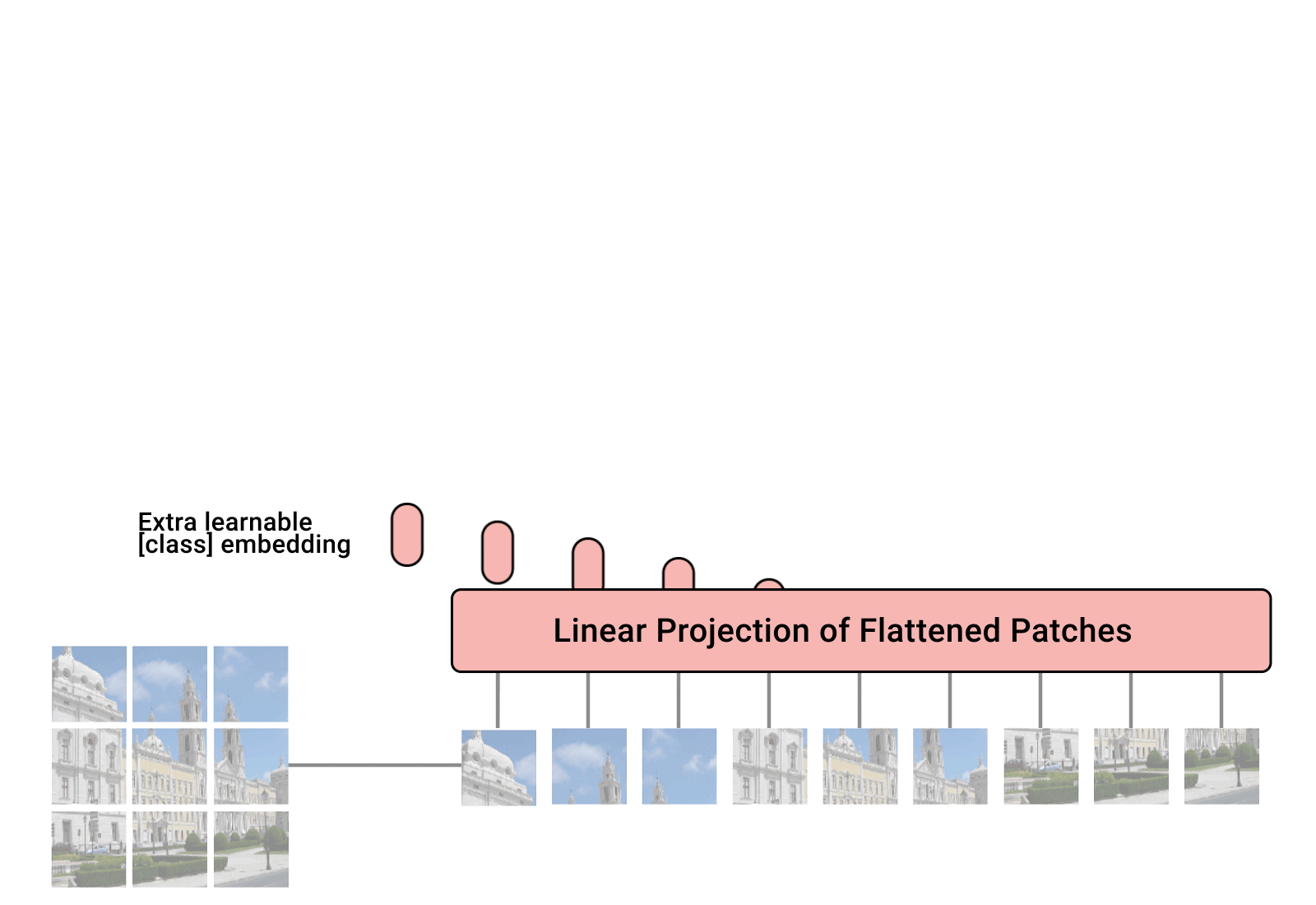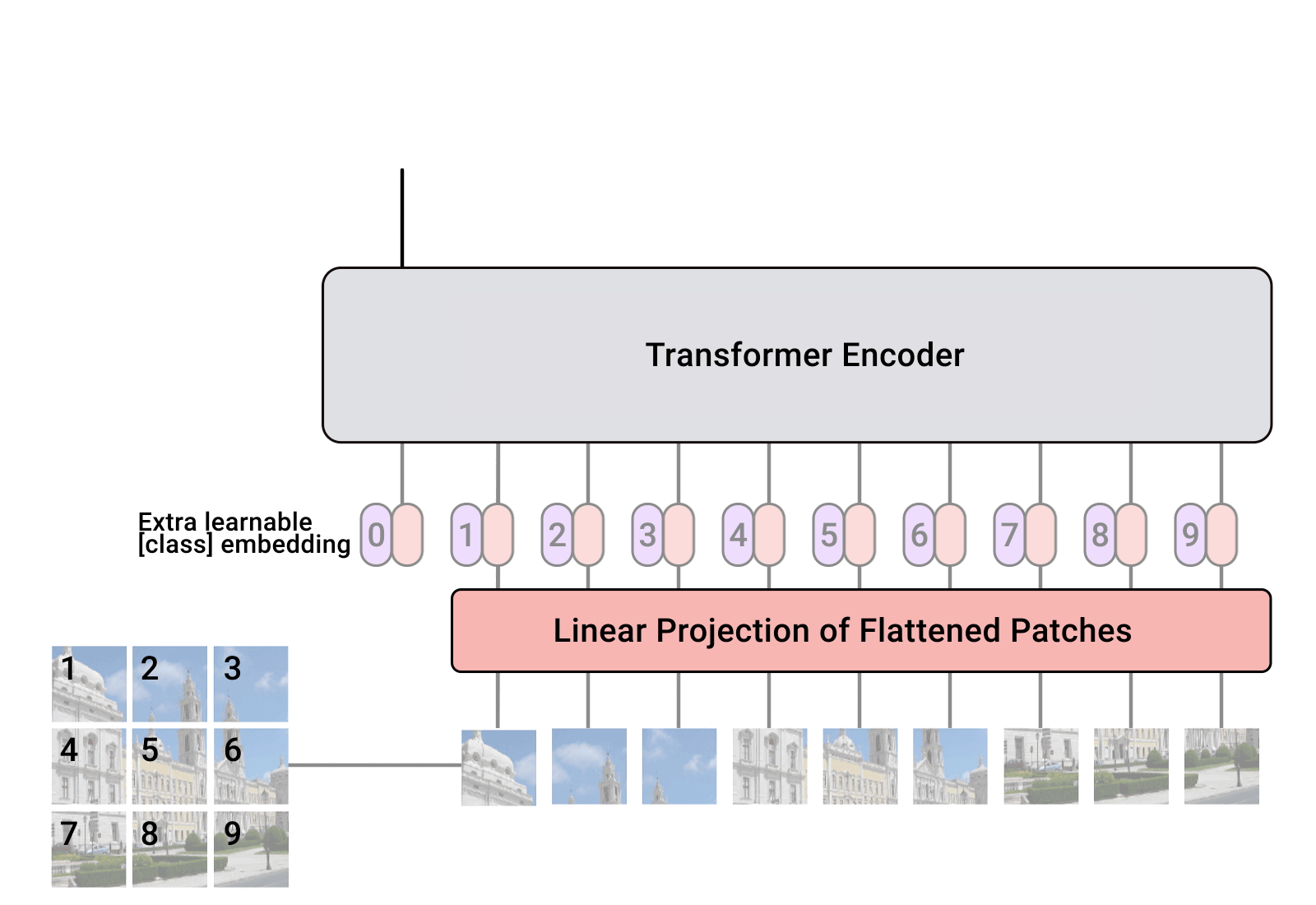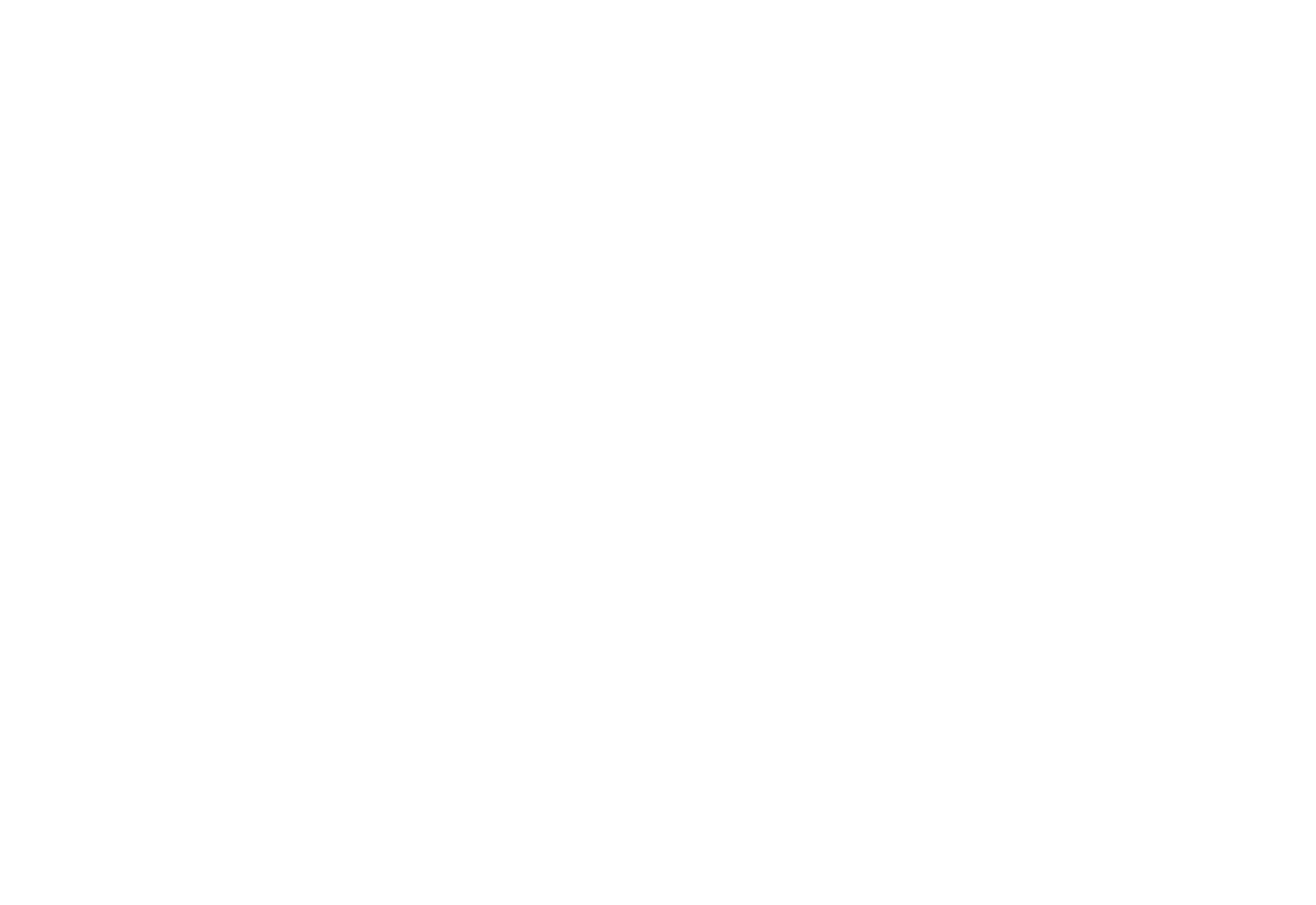
Linear Projection of Flattened Patches
Transformer의 Input 값은 1차원 시퀀스 입니다. 따라서, 고정된 크기의 patch로 나눠준 이미지를 1차원 시퀀스로 flattened해야합니다. 수식으로 표현하면, H x W x C 형식의 이미지를 N x (P x P x C)로 변환해야 합니다.
H는 이미지의 높이, W는 이미지의 넓이, C는 이미지 채널입니다. N은 시퀀스 수, P x P는 이미지를 나누는 고정된 patch의 크기입니다.
이렇게 1차원으로 바꾼 이미지를, Transformer에 사용할 수 있는 D차원의 백터로 바꿔줍니다. 이걸로 Transformer Input 형식에 맞춰서, 이미지를 바꿨습니다.
참고로 Hybrid Architecture로 CNN의 feature map을 Input 값으로 사용할 수도 있다고 합니다. 우리는 CNN 없는 모델에 집중하도록 하죠.
수식으로 보는 ViT

입력에 해당하는 수식입니다. Xclass는 classification token입니다. XNpE는 patch로 나눈 각각의 이미지 시퀀스입니다. 마지막 Epos는 각각 시퀀스의 순서를 나타네는 Positional Encoding입니다.

Transformer에 해당하는 수식입니다. 이전 입력 값에 Layer Normalization한 후에, Multi-head Attention을 적용합니다. 해당 값을 skip connection을 해줍니다.

MLP head에 해당하는 수식입니다. 위에서 설명한 부분과 동일한 것은 생략하고, Transformer에서 나온 값을 MLP합니다.

마무리로 나온 학습 Class를 찾습니다. 조금 장황한 설명이 끝났습니다.
ViT 사용에 유의할 점
당연한 이야기지만, ViT도 Transformer 답게 많은 데이터로 Pre-Training 하지 않으면, 좋은 성능을 기대하기 어렵습니다. ViT 모델은 구글 내부 이미지 6억장 정도로 Pre-Training 됐다고 합니다. 따라서 공개된 모델을 Fine-Tuning하여, 사용하는 것이 좋습니다.
Fine-Tuning시에는 Pre-Training prediction head를 제거하고, 0으로 초기화된 D x K 차원의 feedforward layer를 연결하여, 사용하면 됩니다. 여기서 K는 우리가 풀려는 테스크의 Class 개수입니다.
재밌게도 Fine-Tuning할 때는 Pre-Training 이미지보다 높은 해상도의 이미지를 쓰는 것이, 성능 향상에 좋다고 합니다. 그럼, patch 크기를 동일하게 유지하고 더 큰 시퀀스 수를 사용할 수 있습니다. N x (P x P x C)에서 N이 늘어날 수 있는 거죠. (데이터가 많아지니, 성능이 높아지는 걸까요?)
ViT는 메모리의 한계까지, N의 길이를 늘릴 수 있습니다. 당연한 말이지만, N의 길이가 늘어갈 경우, Pre-Training 모델의 position embedding은 더 이상 의미가 없을 수도 있습니다. 이럴 때만 2차원 구조를 사용하여, position embedding을 조정합니다.
성능


사실 성능은 말할 필요가 없습니다. 이 논문이 의미 있는 이유죠. 다만 Pre-Training 데이터 적다면, 성능이 안 좋아집니다. ViT에서는 Pre-Training 데이터가 많아야 된다는 사실을 기억합시다.


ViT 연구

당연하게도 Attention을 잘 합니다.

맨 왼 쪽을 봅시다. embedding filter를 시각화한 결과입니다. 흥미롭게도 많은 데이터를 Pre-Training하면, embedding filter가 CNN filter와 비슷한 기능을 보입니다.
가운대 그림을 보죠. Postion embedding을 시각화했습니다. 각각의 위치를 잘 학습한 것을 볼 수 있습니다. Postion embedding에서 이미 2차원의 이미지를 나타내는 법을 학습한 것으로 보입니다.
마지막 그림을 봅시다. 낮은 layer는 CNN의 낮은 layer처럼 각각의 이미지를 나타냅니다. 그러다 마지막에 가서는 이미지의 통합적인 모습을 나타냅니다.
참고
[논문리뷰] Vision Transformer - An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
** 작년에 공개된 구글 리서치 논문입니다 ** An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (A.K.A) Vision Transformer 개요 비전 AI도 CNN없이 풀 수 있다! Transformer만을..
littlefoxdiary.tistory.com
[논문요약] Vision분야에서 드디어 Transformer가 등장 - ViT : Vision Transformer(2020)
*크롬으로 보시는 걸 추천드립니다* https://arxiv.org/pdf/2010.11929.pdf 종합 : ⭐⭐⭐⭐ 1. 논문 중요도 : 5점 2. 실용성 : 4점 설명 : 게임 체인저(Game Changer), Convolutional Network구조였던 시각 문제..
kmhana.tistory.com
[논문리뷰] Vision Transformer(ViT)
논문에 대해 자세하게 다루는 글이 많기 때문에 앞으로 논문 리뷰는 모델 구현코드 위주로 작성하려고 한다. AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE Alexey Dosovitskiy∗,..
visionhong.tistory.com
[논문] 최근 AI의 이미지 인식에서 화제인 "Vision Transformer"에 대한 해설
※ 일본 블로그 내용을 번역한 것으로 오역이나 직역이 있을 수 있으며, 내용의 오류 지적해주시면 감사하겠습니다. 1. 개요 현재 AI계에서 화제가 되고 있는 "Vision Transformer"에 대해 다뤄보려고
engineer-mole.tistory.com
[논문리뷰] An Image is Worth 16X16 Words: Transformers for Image Recognition at Scale
An Image is Worth 16X16 Words: Transformers for Image Recognition at Scale Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob U
jeonsworld.github.io
[논문 리뷰] ViT(Vision Transformer) : AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
오늘은 NLP에서 엄청난 성능을 보여주고 있는 트랜스포머를 비전 분야에 적용한 Vision Transformer에 대해 리뷰해보고자 한다. 이름만 들어보고 방법론에 대해 아예 몰라서 궁금하고 기대된다. Abstrac
simonezz.tistory.com
초 간단 논문리뷰 | Vision Transformer(ViT), Google
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE 논문 https://arxiv.org/pdf/2010.11929.pdf code https://github.com/google-research/vision_transformer 참고 https://www.youtu..
everyday-deeplearning.tistory.com
'논문 리뷰' 카테고리의 다른 글
| LANGUAGE MODELS ARE UNSUPERVISED MULTITASK LEARNERS, GPT-2 논문 리뷰 (0) | 2020.02.15 |
|---|---|
| Improving Language Understanding by Generative Pre-Training (GPT) 논문 리뷰 (0) | 2020.02.15 |
| BAM: BOTTLENECK ATTENTION MODULE 논문 리뷰 (0) | 2020.02.09 |
| NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE 논문 리뷰 (0) | 2020.02.09 |
| ATTENTION IS ALL YOU NEED 논문 리뷰 (2) | 2020.02.09 |



