Deep neural networks의 성능 향상을 도와주는 BAM : Bottleneck Attention Module을 리뷰를 해보겠다.
한국어 리뷰와 논문 그리고 Github을 참고하여 읽어보자.

ResNet, WideResNet, PreResNet, MobileNet 등에서 테스트를 통해서 성능향상을 확인했다.
Introduction, Related Work 간단한 요약
BAM(Bottleneck Attention Module)은 DNN의 성능을 향상해준다.
We explicitly investigate the use of attention as a way to improve network’s representational power in an extremely efficient way.
네트워크 성능을 효율적으로 향상하는 방법을 조사한다.
Our main contribution is three-fold.
우리의 목표는 3가지다.
- 우리는 단순하고 효과적인 모듈인 BAM을 제안한다. CNN과 쉽게 통합할 수 있다.
- 광범위한 연구를 통해 BAM의 디자인을 검증한다.
- 여러 벤치마크 (CIFAR-100, ImageNet-1K, VOC 2007 및 MS COCO)에서 다양한 기준 아키텍처를 사용하여 BAM의 효율성을 검증합니다.
We find an efficient location to put our module
우리는 모듈을 배치할 수 있는 제일 좋은 위치를 찾았다. 위치는 아래 Figure. 1에서 보자.
Figure 1

BAM integrated with a general CNN architecture
기존에 CNN과 다른 점은 BAM 블록이 있어서 이를 통해서 DNN의 성능을 높여준다.
BAM integrated with a general CNN architecture 그림과 같이 BAM은 네트워크의 모든 병목 지점에 배치된다. 흥미롭게도, 우리는 인간의 지각 과정과 유사한 계층적 주의를 구축하는 여러 BAM을 관찰할 수 있다.
- BAM은 초기 단계에서 배경 텍스처 기능과 같은 저수준 기능을 제거한다. 그러니까 Hierarchical attention maps 첫 번째 그림처럼 고양이의 주변 배경들이 제거되고 고양이 모습만 남게 되는 거를 볼 수 있다.
- 그런 다음 BAM은 점차 높은 수준의 정확한 대상에 집중한다. Intermediate feature maps부분에 Stage 3 그림을 보면 빨간색 초록색 등등 다양한 색을 보이며 Stage 2보다 높은 수준의 의미를 이해했다고 볼 수 있다.
- 점점 더 많은 시각화 및 분석이 포함됩니다. 마지막 그림을 보면 높낮이 등이 포함된 것으로 보이는 더 자세한 내용을 이해했다고 볼 수 있다.
- Hierarchical attention maps이 점점 흐려지는 이유는 학습하면서 점점 pixel이 뭉개지는 것과 범용적으로 쓰기 위해서 일 것이라고 생각한다. 하나의 그림을 그대로 학습하는 것이 아니라 해당하는 그림의 패턴을 찾아서 여러 고양이을 찾기 위해서 일 것이다. 그러므로 점점 패턴으로 Hierarchical attention maps이 점점 흐려진다고 생각할 수 있다.
3 Bottleneck Attention Module
Show, Attend and Tell

이미지 출처 : http://kelvinxu.github.io/projects/capgen.html
이 논문에서 Attention 즉, 더 집중해야 할 요소에 집중을 하는 모습을 보여준다. 이를 이해하기 쉽게 Show, Attend and Tell를 본다면 각각에 중요한 요소들을 찾는 것을 볼 수 있다.
수식

M(F)를 찾는 수식
M(F)는 두 방향으로 연산하는데 결과적으로 sigmoid function을 적용해서 0~1 사이의 값을 가진다.

F'을 찾는 수식
F'은 0~1 사이의 값을 가지는 M(F)와 F가 ⊗ 연산하고 이전 값과 합친다. 쉽게 생각하면 M(F)에서 중요한 부분들을 찾아서 가중치를 높여서 더한다고 생각하면 된다.

Mc(F)를 찾는 수식
channel vector Fc로부터의 채널들에 걸친 중요도를 평가하기 위해, 우리는 하나의 hidden layer를 갖는 MLP(multi-layer perceptron)를 사용한다.
MLP 후에 우리는 BN(batch normalization) layer를 추가하여 스케일을 조정한다.
즉, 위 수식의 과정을 정리하면 여러 채널이 있는데 그 채널 중 중요한 채널을 높여서 강조해준다. 이해가 안 된다면 Show, Attend and Tell를 다시 보자.
Figure 2

효율적이지만 강력한 모듈을 설계하기 위해, 우리는 branches를 두 개의 나눠서 계산한다. Mc(F)(Channel attention)와 Ms(F)(Spatial attention)를 먼저 계산하고 결과 값을 더하고 sigmoid function을 적용해 M(F)(BAM attention)을 만든다. 그 후는 위에서 설명한 F'을 찾는 수식에서 설명한 행위를 실행한다.

F'을 찾는 수식
Figure 2는 위 수식을 그림으로 자세히 설명한 것이다.
Ms(F)(Spatial attention)는 의미를 유지하기 위해 1 X H X W로 만든다. 마지막에 1 X 1 CONV로 Rc 부분을 1로 바꾼 것을 제외하면 기본적인 CNN과 비슷한 연산을 한다.
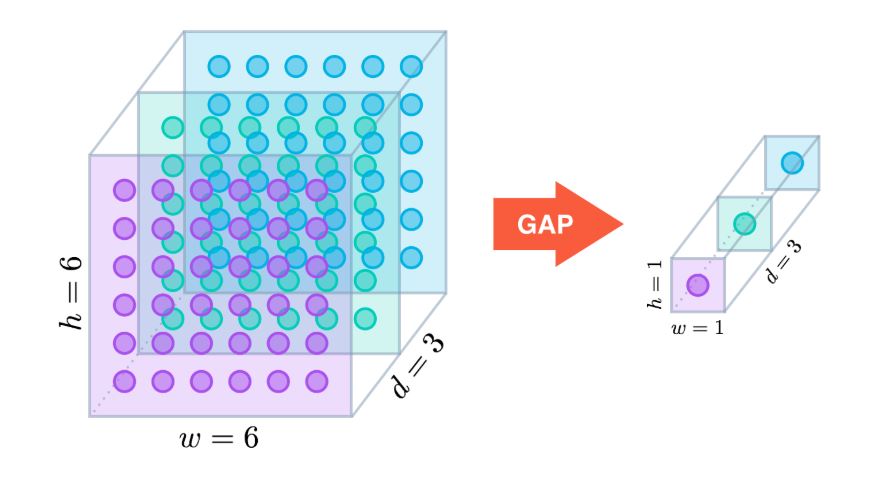
사진 출처 : https://alexisbcook.github.io/2017/global-average-pooling-layers-for-object-localization/
Mc(F)(Channel attention)는 Global avg pool을 통해서 H X W를 1 X 1로 바꾼다.
branches를 두 개로 나눈 이유
예를 들어 1000 X 1000 X 1000의 network를 연산한다면 엄청난 연산과 overfitting이 발생할 수 있다. 하지만 만약에 2개로 나누면 1 X 1000 X 1000과 1000 X 1 X 1를 더하면 되는 것으로 훨씬 간단하게 연산을 수행할 수 있다.
궁금한 점
Sigmoid는 항상 0~1 값으로 즉, F\'= F+F⊗M(F)에서는 값이 -가 되지 않는다. Tanh를 한다면 -가 될 수도 있는데 말이다. M(F)에서 Sigmoid를 사용하기에 항상 +가 돼서 값이 계속 올라가는 것만 가능한데 왜 그렇게 하는지 모르겠다. 그리고 다른 논문들도 Sigmoid를 많이 사용하는데 이유가 있는 것인지, Sigmoid가 편해서 인지 모르겠다.
4 Experiments

4.1 Ablation studies on CIFAR-100

4.1 Ablation studies on CIFAR-100

4.1 Ablation studies on CIFAR-100

4.3 Classification Results on ImageNet-1K

4.6 VOC 2007 Object Detection
BAM 적용으로 각종 실험에서 1% 정도 수준의 성능 향상이 있는 것을 확인할 수 있다.
Conclusion
BAM 적용을 적용하면 여러 vision 작업에서 성능향상이 가능할 것으로 보인다. 그리고 궁금한 점에서 이야기한 Tanh를 적용해보는 테스트해 볼 예정이다. 만약에 성능향상이 더 된다면 새로운 논문을 쓸 수 있지 않을까?



