GPT로 알려진 Improving Language Understanding by Generative Pre-Training 논문을 리뷰해보자! ATTENTION IS ALL YOU NEED 논문에서 소개한 Transformer Decoder를 12 쌓은 구조다.

ABSTRACT
labeling 되지 않은 text corpora data가 충분하지만, 특정 task를 학습시키기 위한 labaling 된 data가 부족한 경우가 많다. 예를 들어 한국어의 경우 labaling 되지 않은 네이버 뉴스, 위키 같은 text corpora가 충분하지만 블로그의 품질을 체크 하는 labeling data가 충분하지 않을 수 있다. 이러한 문제는 실상 현실 세계에서 자주 발생한다. 이 논문에서는 unlabeling 된 text data를 language model로 pre-training을 진행한 후, 필요한 task에 대한 fine-tunning하는 것이 효과가 있음을 보인다. 이전에 접근과 다르게, 모델 구조의 작은 수정만으로 효과적인 결과를 보여준다. 12 task에서 9개나 SOTA를 달성했다. commonsense reasoning 8.9% 향상 question answering 및 textual entailment 1.5% 향상을 하면서 우수성을 보여준다.
Introduction
과거에는 labeling되지 않은 text data를 이용하여, 부족하지만 labeling 된 text data의 성능 향상을 도모할 수 있다는 생각을 하지 않았다. 해당 data로 word label 이상의 정보를 활용하는 것은 2가지 이유로 어려웠다. 어떤 optimization 방법이 효과적인지 불분명하고, 어떻게 해야지 학습된 representation이 원하는 task에 효과적으로 적용되는 의견일치가 되지 않았다. 그래서 간단한 한 가지 모델을 이용한 pre-tunning 방법이 없었고 semi-supervised learning이 어려웠다.
이 논문에서는 위에서 설명한 것과 같이 labeling 되지 않은 text data로 network를 학습하는 pre-training을 진행한다. 이후 target task에 맞는 fine-tunning을 진행한다. 당시 nlp task에서 가장 좋은 성능을 보여준 transformer을 사용했다.
Framework
학습 단계별로 GPT가 어떻게 학습을 하는지 살펴보자!
Unsupervised pre-training
unsupervised corpus tokens U={u1,…,unu1,…,un}가 주어지면, 아래의 likelihood를 최대화하는 standard language modeling objective가 적용된다.

간단게 생각하면, k(context windows size) 만큼의 unsupervised corpus tokens을 이용해서 현재 token ui를 예측하는 것이다.

U=(u−k,…u−1) 는 token의 context vector, n은 layer 수, We는 token embedding matrix, Wp는 position embedding matrix이다.
처음(h0) -> 에는 필요한 해당 token을 position embedding으로 순서 값을 정해주고, hl -> 계속해서 transformer_block에 넣어줘서 학습을 진행한다. 결과(Pu)는 학습된 마지막 값을 행렬 곱하여 text dictionary만큼의 softmax로 다음 단어를 뽑아낸다.
Supervised fine-tunning
labeld dataset C를 가지는 traget task에 대해 parameters를 조정한다. sortmax를 통해 input tokens x1,…,xm에 해당하는 label y를 예측한다.
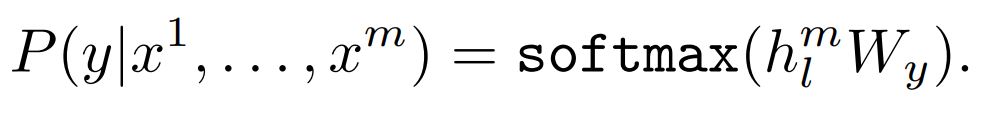
위에 pre-training 작업의 결과 P(u)을 input으로 하는 linear layer를 추가한다.

추가적으로 fine-tunning에 auxiliary objective로 포함하는 것이, supervised model의 generalization을 향상하고, 모델이 빠르게 수렴하도록 하여 학습에 도움된다. 다음의 objective를 최적화한다.
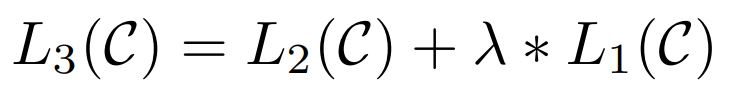
Task-specific input transformers
각각의 task에 대해서 아래와 같은 방식으로 변형을 한다.

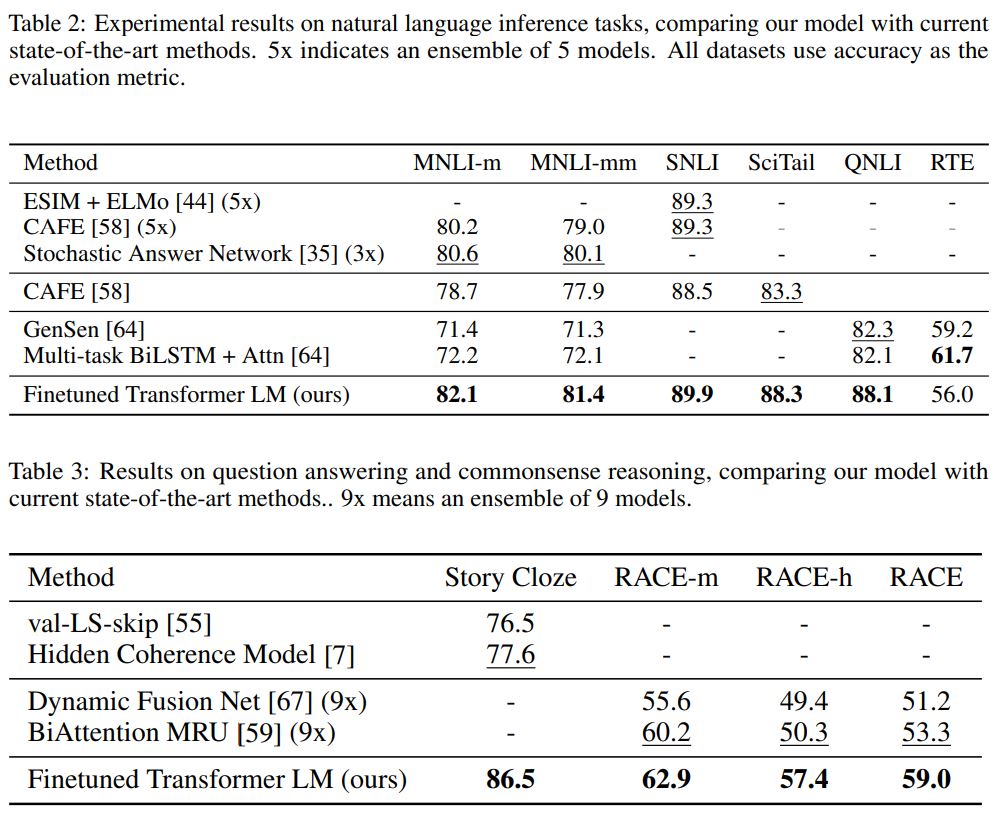
Experiments
결과는 아주 환상적이다.

Analysis
Impact of number of layers transformer
layer를 추가하면 추가할 수록 성능이 향상하는 것을 보며, pre-train model의 각 layer는 target task를 풀기 위한 유용한 정보를 가지고 있는 것을 알 수 있다.

Ablation studies
아래 결과로 Ablation studies의 효과를 알 수 있다. 하지만 Dataset의 크기가 작을 경우 fine-tunning만 하는 것이 성능이 더 좋다.

Conclusion
이 논문이 GPT, Bert, T5 등 transformer model을 이용하여, generative pre-training과 discriminative fine-tunning을 통해 강력한 NLU(natural language understanding)을 할 수 있다는 것을 증명하며, 해당 방법의 신호탄을 연 논문이다.



