RNN이나 CNN이 아닌 새로운 구조를 개척한 Attention Is All You Need을 리뷰를 해보겠다.
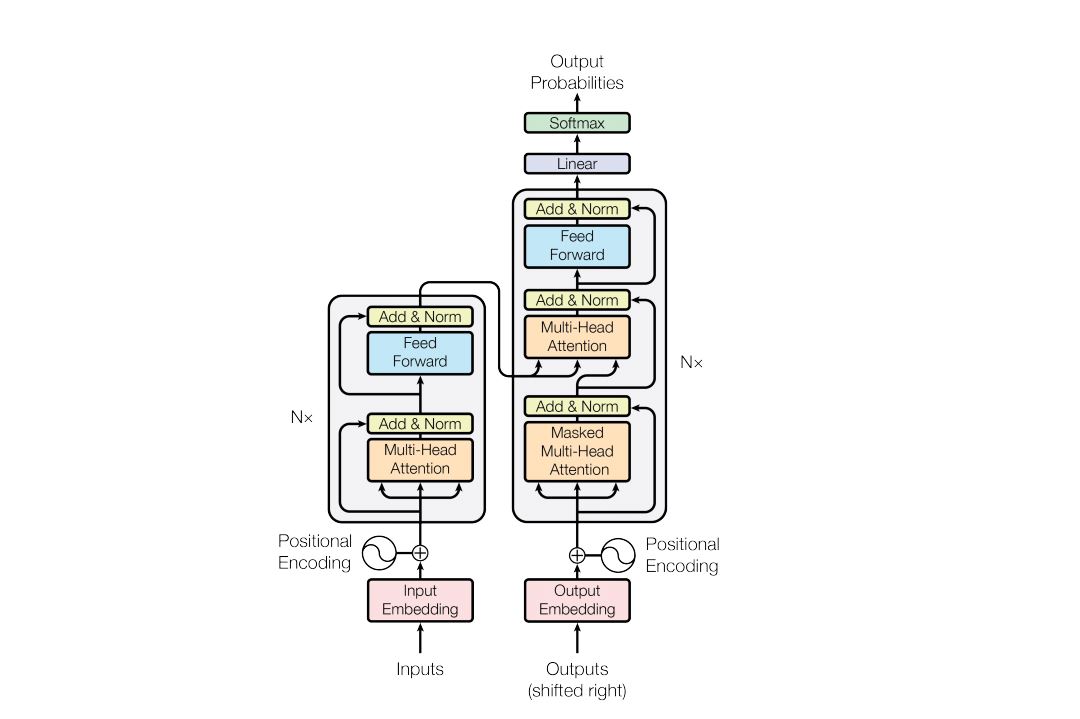
특이한 구조를 가지고 있다.
ABSTRACT
sequence transduction models는 encoder and a decode를 포함하는 복잡한 recurrent or convolutional neural networks에 기초한다. 가장 성능이 좋은 모델은 attention mechanism을 통해 encoder and decode를 연결한다. 우리는 recurrence and convolutions neural networks를 제거하고 오로지 attention mechanisms에만 기초한 새롭고 간단한 network 구조를 제안한다.
machine translation 작업에 대한 실험 결과를 보면 이 모델은 병렬 처리가 가능하고 학습 시간이 훨씬 덜 소요되는 동시에 품질이 우수한 것을 확인했다. 그리고 2014년 WMT Englishto-German 번역 대회에서 28.4 BLEU를 달성하면서 기존 최고 모델보다 2BLEU 이상 향상하며 state-of-the-art를 달성했다.
우리는 Transformer가 크고 제한된 훈련 자료로 영어 문법 해석에 성공적으로 적용됨으로써 다른 tasks에서도 잘 일반화됨을 보여준다.
Introduction
RNN, LSTM, GRU는 언어 모델링 및 기계 번역과 같은 시퀀스 모델링 문제에서 확고히 자리를 잡았다. 하지만 Recurrent 모델은 필연적으로 이전 결과를 입력으로 받는 순차적 특성 때문에 병렬처리를 배제한다. 최근의 연구는 factorization tricks과 conditional computation을 통해 연산 효율의 대폭적인 향상을 달성했다. 하지만 아직까지 순차적 계산의 근본적인 제약은 여전히 남아있다.
아직까지도 (이 논문은 2017년에 작성되었다) 대부분은 attention mechanisms도 recurrent network와 함께 사용된다.
우리는 Recurrent 모델의 제약 사항들을 피하고 입력과 출력 사이에 전역 의존성을 이끌어내기 위해 Transformer을 제안한다. (Transformer은 병렬화가 가능하고 높은 성능을 자랑한다)
Model Architecture

Attention만으로 encoder-decoder 구조를 가진 모델
Encoder
- Encoder는 N = 6개의 동일한 층으로 구성되어 있다. 처음 input이 첫 번째 층에 들어가고 그 다음 층은 이전 층의 결과값이 들어가는 식이다.
- 각 층에는 2개의 sub-layers가 있다. 첫 번째는 multi-head self-attention이고 두 번째는 단순하게 완전 연결된 feed-forward이다.
- 우리는 2개의 sub-layers 주의에 residual connection을 채택하고 있다. 그리고 layer normalization를 진행한다.
- 각 sub-layers의 출력은 LayerNorm(x + Sublayer(x))이다. 이러한 residual connections을 용이하게 하기 위해 모델의 모든 레이어는 512 차원으로 임베딩한다.
Decoder
- Decoder도 Encoder와 같이 N = 6개의 동일한 층으로 구성되어 있다. 이외에도 residual connection을 수행한 후 layer normalization을 진행하는 것도 동일하다.
- Decoder는 각 층에는 2개의 sub-layers 이외에도 Encoder 스택의 출력을 통해 multi-head self-attention을 수행하는 3번째 sub-layers를 삽입한다.
- 또 다른 점은 Decoder는 순차적으로 결과를 만들어야 한다. masking을 통해 position i보다 작은. 즉, 미리 알고 있는 output들에만 의존한다.

그림을 통해서 해당 모델이 어떤 식으로 동작하는지 살펴보자.
Attention
이전 논문 리뷰에서 Attention에 대한 개념을 다뤘으니 참고하길 바란다. 여기서 나올 query, keys, values는 각각 previous layer의 hidden state, 이 값들을 통해 Attention을 계산한다.
Scaled Dot-Product Attention
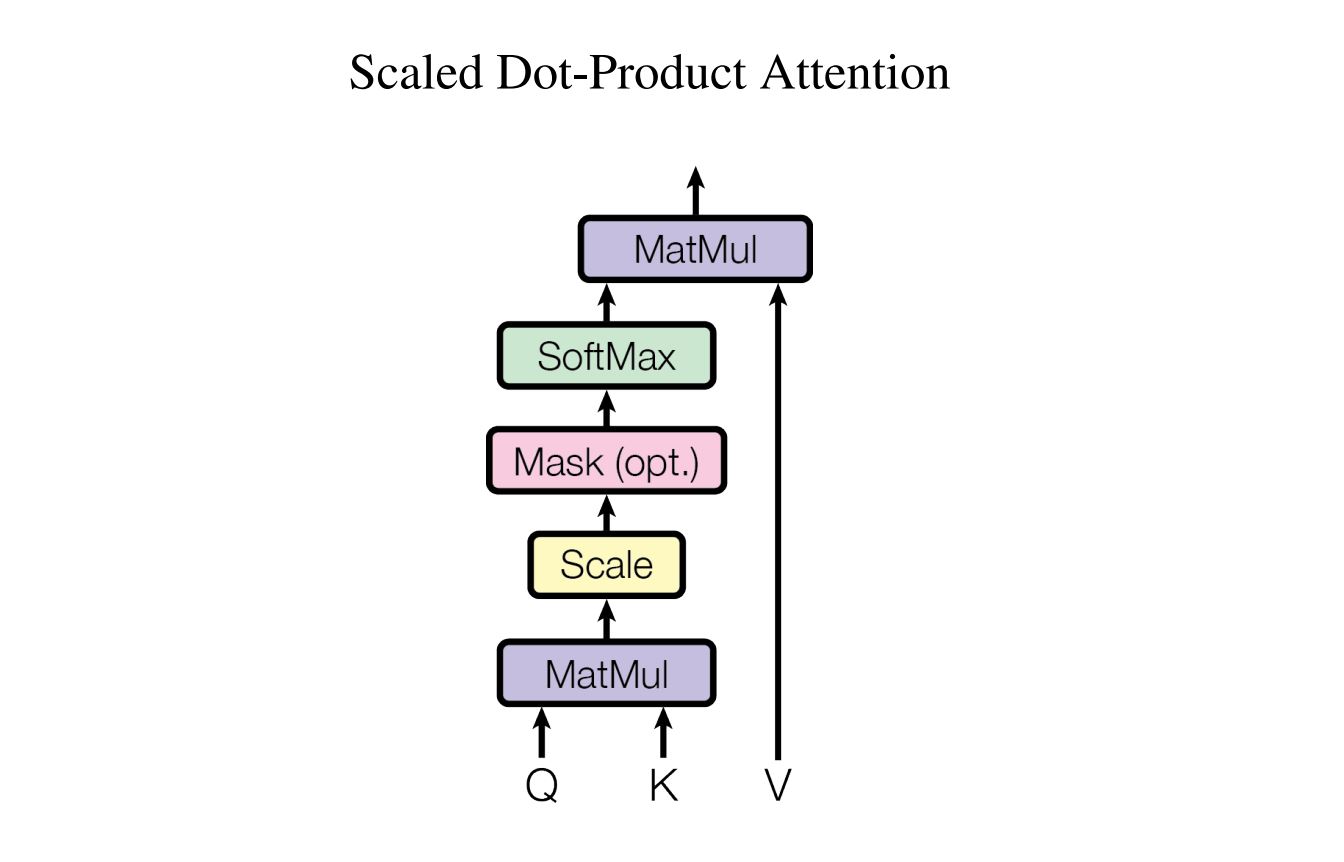
우리의 특별한 attention을 "Scaled Dot-Product Attention"이라고 부른다.
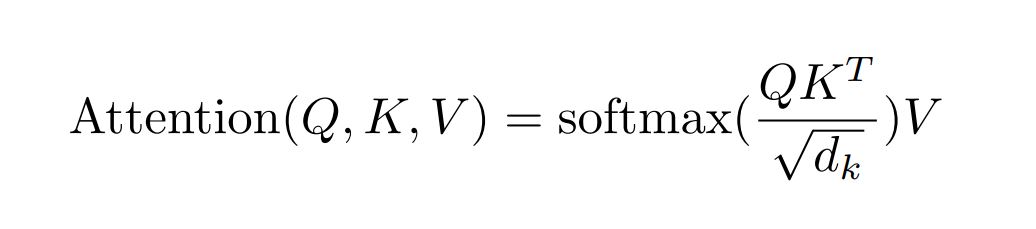
식은 다음과 같다.
입력은 dk 차원의 query와 key 그리고 dv 차원의 value들로 있다. 이하 Q, K, V로 부른다. 먼저 Q와 K를 dot products하고 √dk로 나눈다. 그 후 softmax 함수를 적용해서 value에 대한 weights를 얻어낸다. 즉 Q, K에 맞게 V에 attention을 주는 방식으로 이해했다.
dot products값이 모두 너무 크다면 softmax의 기울기가 작아지기 때문에 1 / √dk 로 dot products한 값을 scale한다.
여기서 Q, K, V란? “encoder-decoder attention”의 경우, Q : 디코더의 이전 레이어 hidden state K : 인코더의 output state V : 인코더의 output state “self-attention”의 경우, Q=K=V : 인코더의 output state
출처: https://dalpo0814.tistory.com/49 [deeep]
Multi-Head Attention
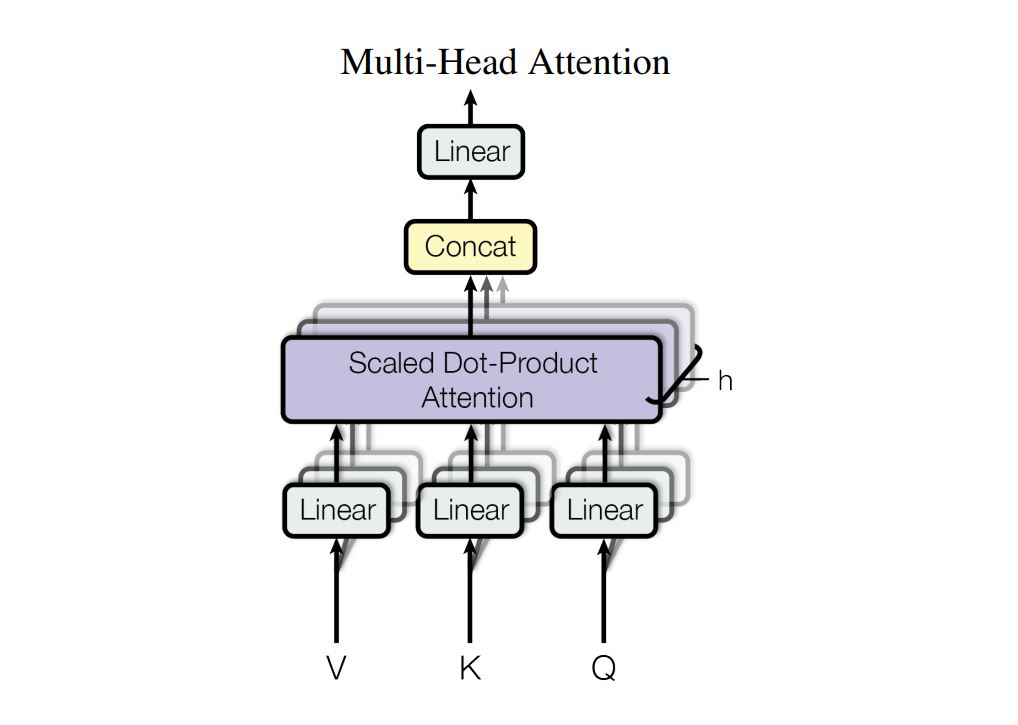
dmodel-dimensional의 keys, values, queries로 단일 attention function를 수행하는 것 보다, dk, dk, dv 차원에 대해 학습된 keys, values, queries Linear를 h번 계산하는 것이 더 좋다고 한다. 이유는 각 벡터들의 크기들을 줄이고 병렬처리가 가능하기에 더 낫다.

각각의 head 즉 keys, values, queries을 h개로 나눈 값들의 attention을 구하고 Concat한다.
Position-wise Feed-Forward Networks
attention sub-layers 외에도, encoder와 decoder의 각 layer는 fully connected feed-forward network를 포함하고 있으며, 이것은 ReLU를 활성함수로 사용하는 두번의 linear transformations으로 구성된다.

Positional Encoding
우리 모델은 rnn이나 cnn이 아니기에 순서에 따라, 시퀀스의 위치에 관한 정보를 주입해야한다. 이를 위해 인코더 및 디코더 스택 하단에 positional encodings을 추가한다. positional encodings은 dmodel(embedding)과 동일한 차원을 갖어 이를 더하는 작업을 할 수 있다.
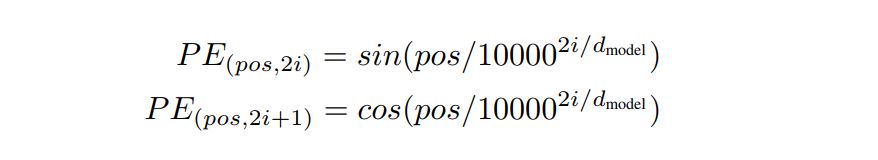
위 식을 이용해서 Positional Encoding을 하고 위치 관련된 정보를 주입할 수 있다.
Why Self-Attention
- 레이어당 계산양이 줄어든다. (n이 d보다 훨씬 작으니까)
- 병렬처리가 가능한 계산이 늘어난다.
- 장거리 학습의 가능 여부이다. Attention을 통해 모든 부분을 확인하니 rnn에 보다 훨씬 먼 거리에 있는 시퀀스를 잘 학습할 수 있다.

다른 기법들과 Self-Attention을 비교한 표
또한 restricted을 이용하여 시퀀스 길이 n이 클때 r크기의 주변만 고려하는 것으로 제안할 수 있다. 관련 논문
다른 이점으로는, self-attention은 문장의 통사적, 의미적 구조를 해석 가능한 모델을 만들 수 있다.
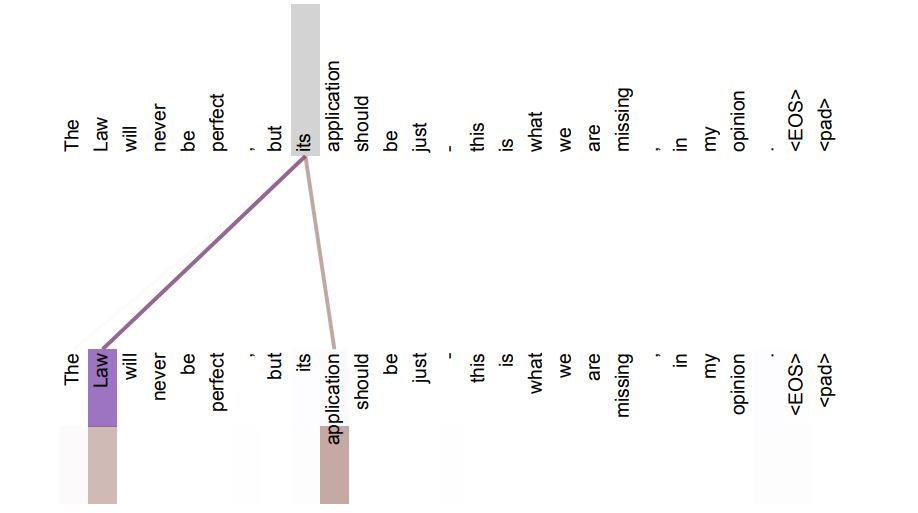
예를 들어 여기서 its가 지칭하는 부분들이 얼마나 유사한지를 시각화하여 문장 내에서의 관계를 해석할 수 있다.
Training
WMT 2014 English-German dataset을 사용했다. NVIDIA P100 GPUs 8대로 기본 모델은 12시간 동안을 big 모델은 3.5일을 학습시켰다.
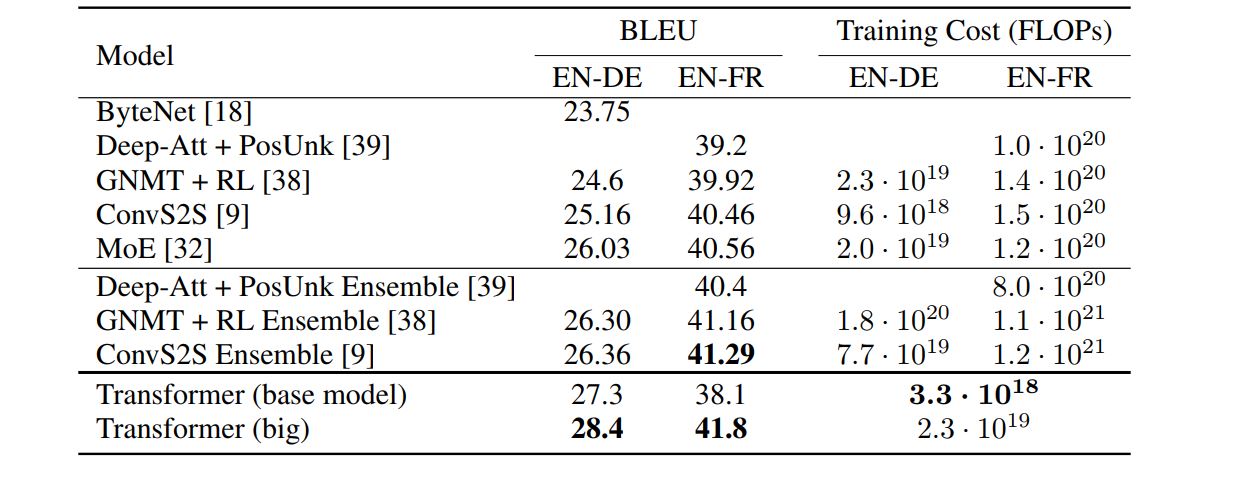
성능에 비해 빠른 속도로 우수한 BLEU scores를 획득했다. 그리고 EN-DE에서는 당시 state-of-the-art를 달성했다.



