코딩 테스트를 준비하기 위해서는 CNN을 직접 tf나 pytorch 없이 numpy 만으로 구현하기, HMM 정도는 numpy도 없이 python으로 코딩하기가 필요하다. 어렵다... pytorch 쓰면 쉬운데..
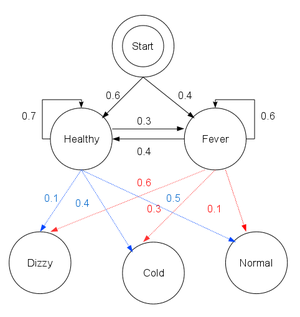
HMM Viterbi (비터비) 알고리즘에 대한 위키피디아 설명이다.
비터비 알고리즘은 은닉 마르코프 모형 등에서 관측된 사건들의 순서를 야기한 가장 가능성 높은 은닉 상태들의 순서(비터비 경로, 영어: Viterbi path)를 찾기 위한 동적 계획법 알고리즘을 말한다.
일반적으로 CDMA, GSM 모두를 포함한 셀룰러 이동통신, 다이얼업 모뎀, 위성 통신, 심우주 통신, 802.11 무선랜에서 사용하는 길쌈 부호를 해독하는 데 사용하였으나 지금은 음성 인식, 음성 합성, 화자 구분, 키워드 검출, 전산언어학, 생물정보학 분야에서도 널리 활용되고 있다. 예를 들어 음성 인식(Speech to Text)에서는 음향 신호를 관측된 사건들의 순서라고 하면, 문자열은 이러한 음향 신호를 야기한 "숨겨진 원인(hidden cause)"으로 간주된다. 이때 비터비 알고리즘은 주어진 음향 신호에 대한 가장 가능성 높은 문자열을 찾아내는 데 사용된다.
비터비 알고리즘은 1967년 잡음 있는 통신 링크 상에서 길쌈 부호의 해독 알고리즘으로 이를 제안한 앤드류 비터비의 이름에서 유래하였다.[1] 그러나 비터비 자신은 물론 니들만-분쉬, 바그너-피셔 등 최소 7번 이상의 독립적인 발견에 의한 복수 발명의 대상으로 본다.
"비터비 경로"와 "비터비 알고리즘"은 확률과 관련된 극대화 문제의 동적 계획법 알고리즘의 표준 용어가 되었다. 예를 들어 통계적 파싱 분야에서 문맥으로부터 자유로운, 가장 가능성 높은 단일 유도체 문자열을 찾아내는 데 사용되는 동적 계획법 알고리즘은 "비터비 파스(Viterbi Parse)"라고 부른다.
https://ko.wikipedia.org/wiki/%EB%B9%84%ED%84%B0%EB%B9%84_%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98
아무튼, 코드는 아래와 같다. 사실상 위키피디아의 코드다. 근데 위키피디아는 띄어쓰기를 제대로 안 해서 보기 힘드니, 이 코드를 보자.
#!/usr/bin/env python
# Code from the wikipedia page for Viterbi algorithm done or modified by Zhubarb
# More implementations of Viterbi algorithm can be found at http://stackoverflow.com/questions/9729968/python-implementation-of-viterbi-algorithm
# Example of implementation of the viterbi algorithm for a primitive clinic in a village.
# People in the village have a very nice property that they are either healthy or have a fever.
# They can only tell if they have a fever by asking a doctor in the clinic.
# The wise doctor makes a diagnosis of fever by asking patients how they feel.
# Villagers only answer that they feel normal, dizzy, or cold.
states = ('B', 'A')
observations = ('x', 'y', 'y')
start_probability = {'A': 0.7, 'B': 0.3}
transition_probability = {
'A': {'A': 0.2, 'B': 0.7, '</s>': 0.1},
'B': {'A': 0.7, 'B': 0.2, '</s>': 0.1}
}
emission_probability = {
'A': {'x': 0.4, 'y': 0.6},
'B': {'x': 0.3, 'y': 0.7}
}
# Helps visualize the steps of Viterbi.
def print_dptable(V):
s = " " + " ".join(("%7d" % i) for i in range(len(V))) + "\n"
for y in V[0]:
s += "%.5s: " % y
s += " ".join("%.7s" % ("%f" % v[y]) for v in V)
s += "\n"
print(s)
def viterbi(obs, states, start_p, trans_p, emit_p):
V = [{}]
path = {}
# Initialize base cases (t == 0)
for y in states:
print(y)
V[0][y] = start_p[y] * emit_p[y][obs[0]]
path[y] = [y]
print(V)
print(path)
# alternative Python 2.7+ initialization syntax
# V = [{y:(start_p[y] * emit_p[y][obs[0]]) for y in states}]
# path = {y:[y] for y in states}
# Run Viterbi for t > 0
for t in range(1, len(obs)):
V.append({})
newpath = {}
for y in states:
(prob, state) = max((V[t-1][y0] * trans_p[y0][y] * emit_p[y][obs[t]], y0) for y0 in states)
V[t][y] = prob
#print("gggg", path[state] + [y])
#print("eeee", path[state], [y])
newpath[y] = path[state] + [y]
print("d",newpath)
# Don't need to remember the old paths
path = newpath
print_dptable(V)
(prob, state) = max((V[t][y], y) for y in states)
return (prob, path[state])
def example():
return viterbi(observations,
states,
start_probability,
transition_probability,
emission_probability)
print(example())
다음으로는 조금 다른 방식으로 코딩하는 방식이다.
import fileinput
class Viterbi(object):
def __init__(self, all_nodes ):
# 선 데이터
line_nodes = []
line_num = 0
# 값 데이터
value_nodes = []
value_num = 0
# 마무리 데이터
end_nodes = []
end_num = 0
for nodes in all_nodes:
if len(nodes) == 1:
if line_num == 0:
line_num = int(nodes[0])
elif value_num == 0:
value_num = int(nodes[0])
elif end_num == 0:
end_num = int(nodes[0])
#print(line_num, value_num, end_num)
# 데이터 구축 완료
line_nodes = all_nodes[1:line_num+1]
value_nodes = all_nodes[line_num+2:line_num+2+value_num]
end_nodes = all_nodes[-end_num:]
end_nodes = [nodes[0].split() for nodes in end_nodes]
# 먼저 맵을 만들어보자.
line_nodes2 = [l[:2] for l in line_nodes]
# 처음 맵
dataset = list(set(sum(line_nodes2, [])))
del(dataset[dataset.index('<s>')])
del(dataset[dataset.index('</s>')])
self.dataset = dataset
#print(dataset)
# 단어 발생 확률 체크
dict_value_nodes = {}
for value_node in value_nodes:
#print(value_node[0])
try:
dict_value_nodes[value_node[0]]
except:
dict_value_nodes[value_node[0]] = {value_node[1] : float(value_node[2])}
else:
dict_value_nodes[value_node[0]][value_node[1]] = float(value_node[2])
#print("bo1", dict_value_nodes)
self.dict_value_nodes = dict_value_nodes
dict_line_nodes = {}
for line_node in line_nodes:
try:
dict_line_nodes[line_node[0]]
except:
dict_line_nodes[line_node[0]] = {line_node[1] : float(line_node[2])}
else:
dict_line_nodes[line_node[0]][line_node[1]] = float(line_node[2])
#print("bo2", dict_line_nodes)
self.dict_line_nodes = dict_line_nodes
# 변수들
self.dataset = tuple(self.dataset)
self.end_num = end_num
self.line_num = line_num
self.value_num = value_num
self.end_nodes = end_nodes
self.line_nodes = line_nodes
self.value_nodes = value_nodes
def graph(self):
#print(self.dataset)
#print("self.dict_value_nodes : ",self.dict_value_nodes)
#print("self.dict_line_nodes : ", self.dict_line_nodes)
#print(self.end_nodes)
# 값 전부 가져오기
G = [{}]
going = {}
for end_node in self.end_nodes:
i = 0
# 첫번째꺼
#print("헤", self.dict_line_nodes['<s>'])
for nodes in self.dict_line_nodes['<s>']:
G[0][nodes] = self.dict_line_nodes['<s>'][nodes]
going[nodes] = nodes
#print(G)
#print(going)
# 나머지꺼
del(self.dict_line_nodes["<s>"])
for t,node in enumerate(end_node):
t = t+1
if len(end_node) <= t:
break
#print("go : ", node, self.dataset)
G.append({})
going2 = {}
# 때려 넣는 부분
for y in self.dataset:
#for da in self.dataset:
# print(y,t,G[t-1][da])
# print(y,t,self.dict_line_nodes[da][y])
# print(y,t,self.dict_value_nodes)
# print(y,t,self.dict_value_nodes[y][end_node[t]])
(probability, where) = max((G[t-1][da] * self.dict_line_nodes[da][y] * self.dict_value_nodes[y][end_node[t]], da) for da in self.dataset)
#print("gggg", [(going[where])] + [y])
#print("ggggg", going2)
G[t][y] = probability
try:
going2[y] = (going[where]) + [y]
except:
going2[y] = [(going[where])] + [y]
#try:
# going2[where]
#except:
# going2[where] = [y]
#else:
# going2[where].append(y)
# 기존에 거는 기억 할 필요 없음
going = going2
t = t-1
#for y in self.dataset:
#print("Y ", y)
#print("now : ",max((G[t][y], y)))
(probability, where) = max((G[t][y], y) for y in self.dataset)
return (going[where]) #[self.dataset])
def find_moving(self):
for end_node in self.end_nodes:
i = 0
for line in self.line_nodes:
#print(i)
if line[1] == "</s>":
# A </s> 0.1
# B </s> 0.1 체크 방법 찾아야지
i+=1
print((end_node))
print("end : ",i, line, float(line[2]))
continue
#print("now : ",line, [(line[1],end_node[i])])
print("now : ",line, self.dict_value_nodes[(line[1],end_node[i])] * float(line[2]))
print(line[1],end_node[i], self.dict_value_nodes[(line[1],end_node[i])], float(line[2]))
# 이제 순서에 맞게 수정만 하면 끝
# 이 아니라 모든 케이스에 맞게 다시 만들기
def forward(self):
print(self.line_nodes)
print(self.value_nodes)
if __name__ == '__main__':
# 데이터 받기 시작
datas = ""
for data in fileinput.input():
datas += data
datas = datas.split("\n")
# 전체 데이터 받기
all_nodes = ([data.split("\t") for data in datas])
# 클래스 만들기
HMM = Viterbi(all_nodes)
#print("뭐시여")
print(" ".join(HMM.graph()))
#HMM.find_moving()
주석이랑 직접 실행을 하면서 보면 알 수 있을 것이다. 데이터 받기 부분을 알아서 고치면 된다. 그리고 위 코드는 여러가지 observations를 받을 수 있는 코드다.
Github는 아래에 있다. 스타눌러주세요
gyunggyung/HMM-Viterbi
HMM Viterbi 알고리즘 코드. Contribute to gyunggyung/HMM-Viterbi development by creating an account on GitHub.
github.com
'IT 이야기' 카테고리의 다른 글
| 연구자의 최신 기술에 대한 생각 (0) | 2020.04.07 |
|---|---|
| AI 인공지능 스타트업 리뷰: 뤼이드, 스캐터랩, 스켈터랩스, 매스프레소, 베이글코드, 하이퍼커넥트, 발란, 딜리셔스, 탭조이코리아, 뱅그샐러드 (14) | 2020.04.07 |
| 필수 면접 질문 (0) | 2020.03.24 |
| 코딩 테스트에 대하여 (11) | 2020.03.11 |
| 개발자로 구직하는 사람들에게 (0) | 2020.03.10 |



